앞에서 pgvector 사용법을 알아보았고, 이어서 영문 데이터와 한글 데이터를 openai embedding 하는 방법을 진행합니다.
- supabase pgvector - 1일차 : supabase 와 pgvector
- supabase pgvector - 2일차 : openai embedding
- supabase pgvector - 3일차 : 한글 embedding
1. openai 임베딩
food reviews 데이터
- 1천건 리뷰 데이터 : Time, ProductId, UserId, 평점, 제목, 본문
- CSV 다운로드 : fine_food_reviews_1k.csv
- embedding 포함 CSV : fine_food_reviews_with_embeddings_1k.csv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
-- drop table if exists foodreview1k;
create table foodreview1k (
id bigserial primary key,
regdt bigint, /* to_timestamp() at time zone 'Asia/Seoul', */
productid text,
userid text,
score smallint,
summary text,
body text
)
-- psql 에서 실행
\copy foodreview1k(id, regdt, productid, userid, score, summary, body) from '$HOME/Downloads/fine_food_reviews_1k.csv' delimiter ',' csv header;
-- embedding, n_tokens 컬럼 추가
alter table foodreview1k add column embedding vector(1536);
alter table foodreview1k add column n_tokens int;
-- 최적화 옵션
SET maintenance_work_mem = '8GB';
SET max_parallel_maintenance_workers = 7; -- speed up build (default=2)
SET max_parallel_workers_per_gather = 4; -- speed up query
-- http 확장 기능으로 openai embedding API 를 호출하여 업데이트
-- 조건 : status = 200 and n_tokens > 0
update foodreview1k src
set
embedding = api.embedding,
n_tokens = api.n_tokens
from (
select id
, ((resp).content::json->'usage'->>'total_tokens')::int as n_tokens
, regexp_replace(
(resp).content::json->'data'->0->>'embedding'
,'[\r\n\t ]', '', 'g'
)::vector as embedding
from (
select id, http((
'POST',
'https://api.openai.com/v1/embeddings',
ARRAY[http_header('Authorization','Bearer $OPENAI_API_KEY')],
'application/json',
'{
"input": "'||'TITLE: '||summary||' BODY: '||body||'",
"model": "text-embedding-3-small"
}'
)::http_request) as resp
from foodreview1k -- limit 100
) as valid_data
where (resp).status = 200
and ((resp).content::json->'usage'->>'total_tokens')::int > 0
) as api
where src.id = api.id;
-- ==> 실패!! (그나마 100건 중 90건만 응답)
-- ERROR: Operation timed out after 5002 milliseconds with 0 bytes received
-- SQL state: XX000
http 확장 기능으로 손쉽게 처리할 수 있을듯 했는데, 역시나 API 응답시간 때문에 timeout 오류로 중단되었다. js 또는 python 으로 수행해야 한다.
js 로 embedding 업데이트
- supabase-js 를 사용해 select 하고 update 수행
- 필터링
WHERE summary IS NOT null OR body IS NOT NULL
- 필터링
- cleanText 에서 텍스트 내의 html 태그와 연속 공백을 제거
- ‘text-embedding-3-small’ 모델을 사용해 임베딩
- 1000 건 임베딩 처리하는데 대략 10분 소요 (token 크기 평균 200~300)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
class OpenaiEmbedding {
#openai;
#db; // supabase
/**
* table 'foodreview1k' embedding
* @returns {number}
*/
async foodreview1k() {
const tableName = 'foodreview1k';
const total = await this.count(tableName);
console.log(`table.size = ${total}`);
const { data, error } = await this.#db
.from(tableName)
.select('id, summary, body')
.or('summary.not.is.null', 'body.not.is.null');
// .limit(1);
if (error) {
console.log(error.message);
return -1;
}
let done = 0;
for (const row of data) {
const content = cleanText(row.summary + ' ' + row.body);
const result = await this.embeddingPrompt(content);
if (result) {
const { error } = await this.#db
.from(tableName)
.update({
n_tokens: result.n_tokens,
embedding: result.embedding,
})
.eq('id', row.id);
console.log(
`[${total}/${done}] id=${row.id}, n_tokens=${result.n_tokens}`
);
if (!error) done += 1;
}
}
return done;
}
}
원본 foodreview1k_embedding 테이블의 id=0 문서로 유사 문서 검색 결과
한정된 table 내에서 거리 기반의 랭킹으로 출력하는 쿼리라서 순위 자체는 이전과 거의 같다. 다만 거리값의 변동이 크다. 원인을 짐작해보면
- 임베딩 대상으로 삼은 텍스트 생성 방식이 정확히 같지 않아서가 큰 원인
- summary 와 body 를 합치고 (동일), 식별자 없이, 이후 html 태그 등을 제거함
cleanText(row.summary + ' ' + row.body)
- 다만, 결과가 나오는 것을 보면 embedding 모델은 같다. (다르면 아예 매칭이 안됨)
- 크든 작든 모델이 변경되면 모든 부분에 큰 영향을 미친다. (전체 테스트 필요)
1
2
3
4
5
6
7
-- TEST : 임베딩 데이터를 가진 id=0 문서와 신규 임베딩 문서간 비교
-- ==> 동일한 embedding 값으로 변환되었음
select id, data.embedding <-> query.embedding as dist, summary
from foodreview1k data,
(select embedding from foodreview1k_embedding where id=0) query
order by dist
limit 5;
| rank | id | dist | summary |
|---|---|---|---|
| 1 | 0 | 0.37783798 | “where does one start…and stop…” |
| 2 | 359 | 1.01080098 | “Wonderful!” |
| 3 | 726 | 1.01620771 | “Perfect treat” |
| 4 | 907 | 1.01908929 | “NTune@60” |
| 5 | 59 | 1.02056843 | “Yummy & Great Small Gift” |
2. airbnb 숙소 추천
이전 포스트의 숙박정보 embedding 데이터를 갱신하여 적용한다.
airbnb_listings 데이터
기존 ‘text-embedding-ada-002’ 대신에 ‘text-embedding-3-small’ 모델로 airbnb 숙박 데이터를 임베딩 처리하기 위해, 테이블을 새로 생성했다.
- 필요한 몇몇 컬럼들만 포함하고
- 컬럼 summary, space, descriptiion, neighborhood_overview 들을 통합
- 별도의 content 컬럼으로 임베딩 수행
- 평균 토큰수 대략 400~500 수준으로 foodreview1k 의 2배 수준
- 임베딩 시간도 7535 건 처리에 140분 정도가 소요됨 (1천건에 20분)
- 그 외에도 대량 호출로 인한 지연 현상도 있는듯
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-- 7573
drop table if exists airbnb_lodging;
create table airbnb_lodging as
select id, name, price
, summary, space, description, neighborhood_overview
, 'SUMMARY '||coalesce(summary,' ')||
'SPACE '||coalesce(space,' ')||
'DESCRIPTION '||coalesce(description,' ')||
'NEIGHBORHOOD_OVERVIEW '||coalesce(neighborhood_overview,' ')
as content
from airbnb_listing
where name is not null;
alter table airbnb_lodging add column embedding vector(1536);
alter table airbnb_lodging add column n_tokens int;
임베딩 유사문서 검색결과 비교
동일한 prompt 에 대해 두 모델의 유사도 상위 10개를 각각 출력해 보았다.
실험1 : 원본 ‘text-embedding-ada-002’ 임베딩 검색 Top 10 결과
- 유사도 최고값이 0.87 로 준수하고, 다양한 숙소가 출력되었다.
- description 만 임베딩 했다.
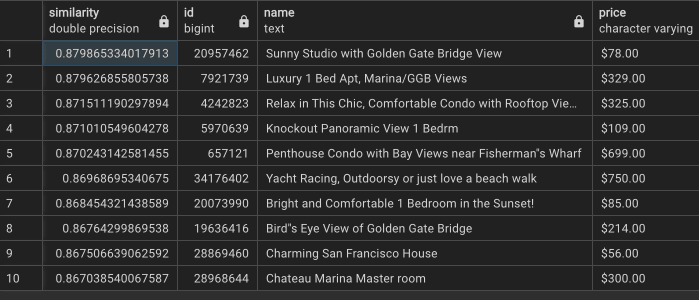
실험2 : ‘text-embedding-3-small’ 임베딩 + 확장 컬럼을 이용한 Top 10 결과
- descriptiion 외에 여러 컬럼을 합쳐서 확장 컬럼을 만들어 임베딩했다.
- 유사도 최고값이 0.61 에 불과하고, 중복 문서가 많다.
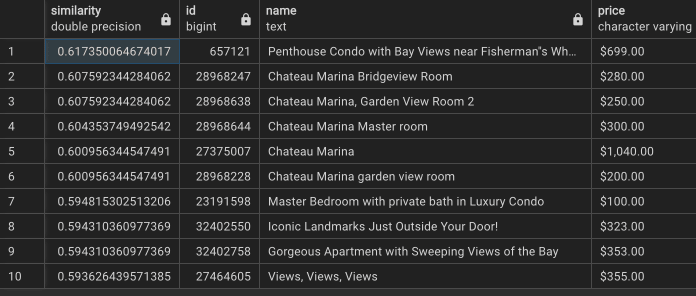
실험3 : ‘text-embedding-3-small’ 임베딩 + 단독 컬럼을 이용한 Top 10 결과
- 실수했음을 깨닫고 descriptiion 만으로 다시 임베딩했다. (small 모델은 싸다)
- 유사도 최고값이 0.62 에 불과하고, 조금 줄어들긴 했지만 여전히 중복 문서가 많다.
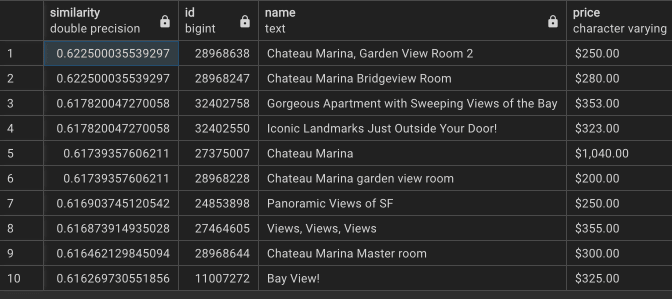
실험4 : ‘text-embedding-ada-002’ 임베딩 + 단독 컬럼의 검색 Top 10 결과
- description 만 임베딩 했다. 원본 임베딩 검색(실험1)과 동일한 결과가 나왔다.
- 유사도 최고값이 0.87 로 준수하고, 다양한 숙소가 출력되었다.
리뷰
모델이 중요하다. small 모델에 비해 ada-002 모델을 사용하니 대번에 유사도가 올라갔다. 돈이 좀 들더라도 large 모델 또는 ada-002 모델로 임베딩해야 한다.
최대한 많은 문서가 매칭되도록 (recall 이 올라가도록) 하려면 풍부한 양의 데이터가 좋지만, 정확도(precision)를 높이려면 관련성이 떨어지는 데이터를 제외해서 액기스만 모아 검색해야 한다.
유사도가 낮게 나온 이유
- descriptiion 외에 여러 컬럼의 텍스트가 포함되면서 매칭되는 벡터 스펙트럼이 넓어졌다. 유사도 분포의 꼭지점도 낮아지는 결과를 낳았다.
중복문서가 많이 나온 이유
- 숙소 공간을 설명하는 부분이나, 주변 지형과 POI 를 설명하는 내용이 여러 문건에 중복되어 나타나는데, 이런 부분에 사용자 prompt 가 매칭되면서 중복 문건들이 걸린듯 하다.
- 임베딩 검색이 적용되는 데이터는 정제하는 전처리 작업과 품질 확인이 필요하다.
3. 한글 뉴스 임베딩
postgres_fdw 원격 테이블 연결
dblink 는 세션 생성시마다 매번 패스워드를 등록해줘야 하는데 반해, postgres_fdw 는 로컬 스키마에 외부 테이블이 등록되어 로컬처럼 사용할 수 있어 더 편리하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
-------------------
-- 원격 서버에서 create role 권한자가 실행
-------------------
-- 외부에서 접속해서 사용할 계정 생성 및 권한 부여 (제한적으로)
CREATE USER fdwDevUser WITH PASSWORD '패스워드';
GRANT USAGE ON SCHEMA jnews TO fdwDevUser;
GRANT SELECT ON jnews.article TO fdwDevUser;
-------------------
-- 로컬 서버에서 실행
-------------------
-- postgres_fdw 확장 기능 설치
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
-- 접속 정보와 함께 외부 서버 등록
CREATE SERVER jnewsdb_fdw
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '외부서버IP', port '포트', dbname '외부DB');
-- 등록된 외부 서버 조회
select * from pg_foreign_server;
-- 로컬 서버의 계정에 외부 서버를 연결 (연결에 사용될 user/password 등록)
CREATE USER MAPPING FOR postgres
SERVER jnewsdb_fdw OPTIONS (
user 'fdwdevuser', password '패스워드'
);
-- 외부 서버와 연결된 계정 조회
select * from pg_user_mapping;
select * from pg_user_mappings; -- 외부 서버 정보와 함께 출력
-- 외부 서버에 대한 사용 권한을 로컬 계정에게 부여
GRANT USAGE ON FOREIGN SERVER jnewsdb_fdw TO postgres;
-- 외부 서버의 스키마와 특정 테이블을 로컬 스키마(tutorial)에 연결
IMPORT FOREIGN SCHEMA jnews LIMIT TO (jnews.article)
FROM SERVER jnewsdb_fdw INTO tutorial;
-- 연결된 (외부 서버의) 외부 테이블을 조회
select * from tutorial.article limit 2;
------------------------------------
-- 삭제 (로컬서버)
DROP EXTENSION IF EXISTS postgres_fdw CASCADE;
REVOKE ALL PRIVILEGES ON ALL TABLES IN SCHEMA tutorial FROM fdwdevuser;
DROP OWNED BY fdwdevuser;
-- 삭제 (원격서버)
REVOKE ALL PRIVILEGES ON ALL TABLES IN SCHEMA jnews FROM fdwdevuser;
DROP OWNED BY fdwdevuser;
DROP ROLE fdwdevuser;
한글 뉴스 데이터 준비
- 테스트를 위해 5천건만 사용한다.
- embedding3-large 모델과 ada-002 모델의 임베딩 결과를 비교하려고 한다.
- embedding3-large 은 small 의 2배수인 vector(3072) 을 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
-- drop table if exists ko_jnews;
CREATE TABLE ko_jnews
(
id bigint generated ALWAYS as identity, -- 또는 by default
url text,
title text,
description text,
content text,
n_tokens int,
embedding_emb3 vector(3072), -- embedding-3-large
embedding_ada2 vector(1536), -- embedding-ada-002
CONSTRAINT ko_news_pk PRIMARY KEY (id),
UNIQUE (url)
);
-- 일단 5천건만 (문서 크기는 대략 6천자 이내로)
insert into ko_jnews(url, title, description, content)
select url, title, description, content
from tutorial.article
where description like '%제주%' and length(content) < 6000
and url not in (
select url
from tutorial.article
group by url
having count(url) > 1
)
limit 5000;
token 최대 개수 제한 때문에 중간에 멈춘 일이 있었다. 그래서 length 조건을 추가했다.
1
2
error: 400 This model's maximum context length is 8192 tokens, however you requested 24324 tokens (24324 in your prompt; 0 for the completion). Please reduce your prompt; or completion length.
code: "null"
임베딩 함수와 검색 쿼리
쿼리 임베딩 함수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
drop function if exists prompt_embedding;
create function prompt_embedding(
input_var text default '제주도 자연보호 행사',
model_var text default 'text-embedding-3-small'
)
returns table(n_tokens int, dims int, embedding vector)
language plpgsql
as $$
declare
openai_api_key_var text := $OPENAI_API_KEY;
begin
-- show input parameters
raise notice '''%'' %', model_var, input_var;
return query
with prompt as (
select (content::json->'usage'->>'total_tokens')::int as n_tokens,
regexp_replace(content::json->'data'->0->>'embedding','[\r\n\t ]', '', 'g')::vector as embedding
from http((
'POST',
'https://api.openai.com/v1/embeddings',
ARRAY[http_header('Authorization', 'Bearer '||openai_api_key_var)],
'application/json',
'{
"input": "'||input_var||'",
"model": "'||model_var||'",
"encoding_format": "float"
}'
)::http_request)
where status = 200
)
select r.n_tokens, vector_dims(r.embedding) as dims, r.embedding
from prompt r
where vector_dims(r.embedding)%1536 = 0; -- dims: 1536 or 3072
end; $$
-- select * from prompt_embedding('제주도 자연보호 행사');
유사문서 조인 검색
1
2
3
4
5
6
7
SELECT 1 - (a.embedding_emb3 <=> u.embedding) as similarity
, a.id, a.title, a.description
FROM ko_jnews a,
prompt_embedding('제주도 자연보호 행사','text-embedding-3-large') u
WHERE 1 - (a.embedding_emb3 <=> u.embedding) > 0.5
ORDER BY a.embedding_emb3 <=> u.embedding
LIMIT 10;
임베딩 모델별 유사도 검색 비교
text-embedding-3-large 모델은 벡터가 2배가 된 만큼, 유사도 값도 절반으로 줄어든 경향을 보인다. 그래도 벡터가 커진만큼 ada-002 모델보다 recall 능력이 좋아졌고 관련성도 상대적으로 높아 보인다.
쿼리1 : ‘어린이 관련 행사’
text-embedding-3-large

text-embedding-ada-002

쿼리2 : ‘금전 지원 사업’
text-embedding-3-large

text-embedding-ada-002

쿼리3 : ‘서귀포 교통 사고’
text-embedding-3-large
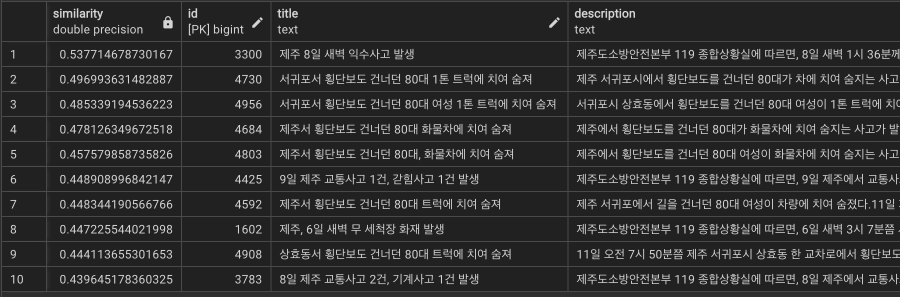
text-embedding-ada-002
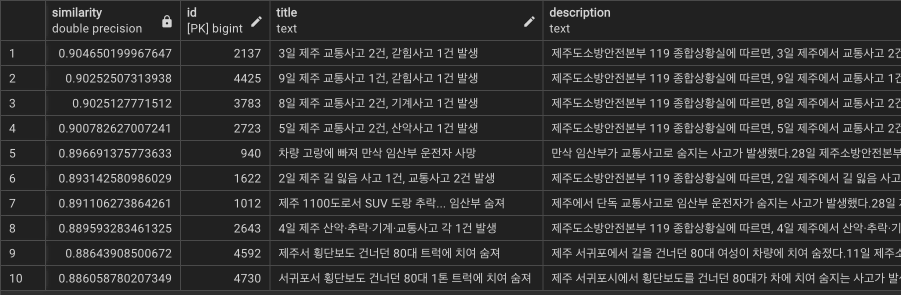
9. Review
- 뭔가 대단한 검색 결과를 기대한건 아니지만, 그렇다고 실망스런 정도는 아니다.
- 텍스트 매칭 방식으로는 쿼리가 일치하지 않으면 나오지 않지만, 임베딩 유사도 검색은 키워드가 일치하지 않아도 비슷한 의미로 매칭하는 편리함이 있다.
- 여기서 더 감동스런 것을 원한다면, 전처리와 후처리가 필요하다. 조금 더 해보자.
- 세상에는 많은 임베딩 모델들이 있고, 그 중 openai 임베딩 모델은 고작 7위에 불과하다.
- 참고 : 임베딩 모델 벤치마킹(MTEB) 최신 순위
- 다른 임베딩 모델 중 다국어 버전들이 따로 있던데, 좀 다를까 싶지만 역시나겠지?
끝! 읽어주셔서 감사합니다.