PostgreSQL(supabase) 에서 한글 검색을 위한 pgvector 사용법을 알아봅니다. 우선은 supabase 와 pgvector 설정부터 시작합니다.
- supabase pgvector - 1일차 : supabase 와 pgvector
- supabase pgvector - 2일차 : openai embedding
1. supabase self-hosting 구성
- supabase docker 깃허브를 다운로드
.env파일의 패스워드들과 (필요시) localhost, port 를 변경- jwt_secret 변경 후 anon_key 와 service_role_key 를 재생성
- docker compose pull
- docker compose up
- 브라우저에서 dashboard 접속 (localhost:8000)
주의사항
- supabase 스택에서 사용하는 port 가 여러개이다. 사용중인 port 를 확인하고 작업하자.
- db(5432), analytics(4000), kong(8000)
- 패스워드, 키 변경 후에 stack 시동시 supabase-analytics 등이 실패하는 issue 가 발생할 수 있다. 이런 경우, 다운로드 한 깃허브 디렉토리 자체를 삭제 후 다시 시작해야 한다.
- 문서대로 잘 따라하기만 하면 mac, ubuntu 모두 잘 됨 (둘 다 해봤음)
- pg data 가 supabase docker 아래 폴더에 저장되기 때문에 실패시 모두 삭제해야함
- 자체 호스팅 버전에는 Dashboard - Settings 메뉴가 숨겨져 있다 (접근 가능)
- JWT, API 설정 등이 비활성화 되어 있어서 바꿀 수 있는게 없다.
- 패스워드, 키를 변경하고 싶으면 최초 설치시
.env에서 설정하고 시작해야 한다.
- jwt 생성시 포함되는 만료시간(exp) 은 발급시간(iat) 기준 1827일(5년+2일) 이후이다.
- 변경하고 싶으면 iat 에 초단위 unix timestamp 값을 더하면 된다.
작업사항
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# Get the code
git clone --depth 1 https://github.com/supabase/supabase
cd supabase/docker
# Copy the fake env vars
cp .env.example .env
# JWT_SECRET 을 이용해 anon, service_role 키를 생성하는게 목적이다.
openssl rand -base64 32 | tr -d '\n'
# ==> $JWT_SECRET 32자 임의의 문자열
vi .env
# 1) POSTGRES_PASSWORD 수정 (username = postgres)
# ==> your-super-secret-and-long-postgres-password
# 2) DASHBOARD_PASSWORD 수정 (username = supabase)
# ==> this_password_is_insecure_and_should_be_updated
# 3) JWT_SECRET 수정 (이후 anon_key, service_role_key 재생성)
# ==> your-super-secret-jwt-token-with-at-least-32-characters-long
# 4) localhost, port 등을 수정
# Pull the latest images
docker compose pull
# Start the services (in detached mode)
docker compose up -d --build
# Stop: docker compose down
# Destroy: docker compose -f docker-compose.yml -f ./dev/docker-compose.dev.yml down -v --remove-orphans
# 확인
docker compose ps
# 접속
psql -h 127.0.0.1 -p 5432 -d postgres -U postgres
# <== $POSTGRES_PASSWORD
# 패스워드 변경 안됨 (변경하고 싶으면 image 를 다시 빌드)
> ALTER USER postgres PASSWORD '<new-password>';
# ==> ERROR: must be superuser to alter replication roles or change replication attribute
테스트
- dashboard 의 Authentication 메뉴에서 사용자 등록 (authenticated 그룹)
- 테이블 생성, RLS 적용, authenticated policy 적용
- 대시보드 테이블 메뉴에서 role 선택하며 데이터 접근 테스트 (auth.uid()=manager)
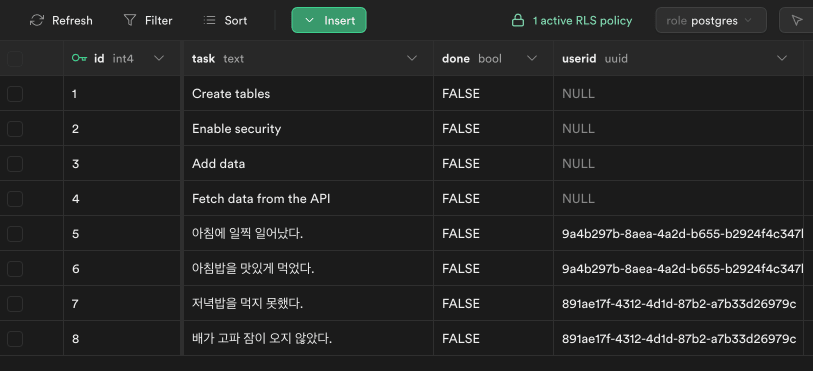
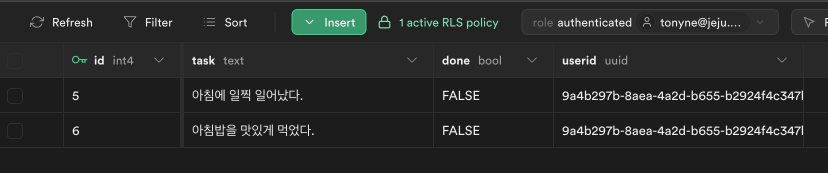
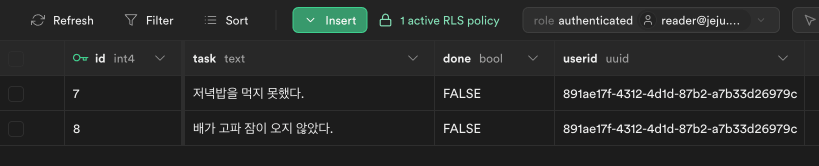
grant 와 RLS 비교
- grant 는 전체 테이블에 대해서만 권한을 부여할 수 있고, 모든 행에 대해 적용됨
- RLS 는 각 행에 대한 액세스를 개별적으로 제어할 수 있음 (manager 값에 따라)
auth.uid(): auth 스키마의 uid 함수 (type = uuid)- current_user : 현재 psql 세션의 role 이름 (ex: ‘postgres’)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
create table "users" (
id serial primary key,
firstname text,
lastname text,
manager uuid default auth.uid()
);
-- Firstname | Lastname | manager
-- ------------------------------
-- Jill | Smith | paul
-- Eve | Dar | paul
-- Arthur | Dent | mary
-- Ford | Prefect | mary
-- RLS 정책
ALTER TABLE accounts ENABLE ROW LEVEL SECURITY;
CREATE POLICY view_users
ON users TO roleB
USING (manager = auth.uid());
-- grant 권한
GRANT SELECT, INSERT, UPDATE, DELETE ON users TO roleB;
참고
- public 스키마에 생성되는 테이블에는 grant 또는 RLS 를 적용하는게 보안상 좋다.
- Postgresql 문서 - DDL of Row Sercurity Policies
2. pgvector 사용하기
pgvector 설치
1
2
3
4
5
6
7
git clone --branch v0.6.0 https://github.com/pgvector/pgvector.git
cd pgvector
sudo make
sudo make install
sudo -u postgres psql -d {DB} -c 'CREATE EXTENSION vector'
supabase 의 pgvector 는
create extension vector만 하면 된다.
1
2
# docker db 인스턴스 접속
psql -h localhost -U postgres -c 'CREATE EXTENSION vector'
pgvector 쿼리
연산자
- L2 거리
embedding <-> '[3,1,2]' - 내적
(embedding <#> '[3,1,2]') * -1 - 코사인 유사도
1 - (embedding <=> '[3,1,2]')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
CREATE TABLE items (
id bigserial PRIMARY KEY,
embedding vector(3)
);
-- 또는 ALTER TABLE items ADD COLUMN embedding vector(3);
-- upsert vectors
INSERT INTO items (id, embedding) VALUES
(1, '[1,2,3]'),
(2, '[4,5,6]'),
(3, '[6,3,1]')
ON CONFLICT (id) DO
UPDATE SET embedding = EXCLUDED.embedding;
-- --------------------------------------------------
-- query : distacne, inner_product, cosine_similarity
-- --------------------------------------------------
SELECT id, embedding,
embedding <-> '[3,1,2]' as dist
FROM items
ORDER BY dist;
-- "id" | "embedding" | "dist"
-- -------------------------------
-- 1 "[1,2,3]" 2.449489742783178
-- 3 "[6,3,1]" 3.7416573867739413
-- 2 "[4,5,6]" 5.744562646538029
SELECT embedding,
(embedding <#> '[3,1,2]') * -1 AS inner_product
FROM items;
-- "embedding" | "inner_product"
-- -----------------------------
-- "[1,2,3]" 11
-- "[4,5,6]" 29
-- "[6,3,1]" 23
SELECT embedding,
1 - (embedding <=> '[3,1,2]') AS cosine_similarity
FROM items;
-- "embedding" | "cosine_similarity"
-- ---------------------------------
-- "[1,2,3]" 0.7857142857142857
-- "[4,5,6]" 0.8832601106161003
-- "[6,3,1]" 0.9063269671749657
-- --------------------------------------------------
-- Aggregation : avg
-- --------------------------------------------------
SELECT AVG(embedding) FROM items;
-- "[3.6666667,3.3333333,3.3333333]"
HNSW 인덱스
Approximate NN(근사적인 근접 이웃) 탐색을 위해 사용되는 그래프 기반 인덱스이다.
- 거리 (L2 distance)
vector_l2_ops - 내적 (Inner product)
vector_ip_ops - 코사인 (Cosine distance)
vector_cosine_ops
1
2
3
4
5
6
7
SET maintenance_work_mem = '8GB';
SET max_parallel_maintenance_workers = 7; -- speed up build (default=2)
SET max_parallel_workers_per_gather = 4; -- speed up query
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops);
CREATE INDEX ON items USING hnsw (embedding vector_ip_ops);
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);
HNSW vs IVFFlat 인덱스 비교
- 인덱스 크기와 빌드 시간이 중요하면 IVFFlat 를 선택 => 대규모 정적 데이터
- lists 크기의 클러스터를 중심점을 기준으로 vector 탐색
- 검색 속도와 업데이트 반영이 중요하다면 HNSW 를 선택 => 소규모 동적 데이터
- multi-layer 그래프 기반으로 가까운 node(vector) 를 탐색
| 비교 | IVFFlat | HNSW |
|---|---|---|
| Build Time (in seconds) | 128 | 4,065 |
| Size (in MB) | 257 | 729 |
| Speed (in QPS) | 2.6 | 40.5 |
| 업데이트 이후 리콜 영향 | Significant | Negligible |
9. Review
- supabase 의 pg 에는 여러 확장 기능들이 준비되어 있어 편리하다.
- Row Level Security 와 policy 도 사용해 보았다.
- 여기까지 하고 다음 문서에서 계속하자.
참고문서
참고 : @supabase/supabase-js 에서 anon_key 가 쓰이는 이유
- supabase-js 는
@supabase/postgrest-js를 기반으로 만들었고 - postgrest-js 는
PostgREST를 기반으로 만들었다. - PostgREST API 를 사용하기 위해서는 anon_key 가 필요하기 때문에
- js 에서 createClient 함수 호출시 anon_key 가 필요하다.
- 혼동되기 싶지만 (API) anon_key 와 (DB) anon role 은 별개이다.
- anon_key 로 pg 접속시 부여받는 role 이 anon 일뿐, supabase.auth 로 로그인 된것은 아니다.
- supabase.auth 로 로그인 되면, authenticated role 을 부여받는다.
- service_role_key 는 service_role 그룹을 부여받고 RLS 를 회피한다.
참고 : supabase - custom schema 사용하기
self-hosting 에서는 추가 schema 를 사용할 수 없다. schema 생성 후에
{PROJECT}/settings/api의 ‘API settings’에서 ‘Exposed schemas’에 custom schema 를 등록해야 하는데, 패널이 비활성화 되어 있어서 할 수 없다. (클라우드에서는 가능)
- supabase issue - Expose non-public schema to supabase-js client
- supabase issue - The schema must be one of the following: public, storage, graphql_public
예시 : tutorial 스키마 추가 후 todos 테이블 RLS 적용하기
- tutorial 스키마를 만들고, RLS 관련 role 들에 권한을 부여한다.
- todos 테이블 생성 후 샘플 데이터도 넣고, anon 정책도 적용한다.
- 설정 메뉴의
API settings > Exposed schemas에서 tutorial 스키마 추가 - PostgREST 재시작을 위해 supabase CLI 또는 대시보드를 이용한다.
supabase stop && supabase start수행- 또는, 대시보드의 database 재시작 버튼 클릭
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
CREATE SCHEMA "tutorial";
GRANT USAGE ON SCHEMA "tutorial"
TO anon, authenticated, service_role;
GRANT ALL ON ALL TABLES IN SCHEMA "tutorial"
TO anon, authenticated, service_role;
GRANT ALL ON ALL ROUTINES IN SCHEMA "tutorial"
TO anon, authenticated, service_role;
GRANT ALL ON ALL SEQUENCES IN SCHEMA "tutorial"
TO anon, authenticated, service_role;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres IN SCHEMA "tutorial"
GRANT ALL ON TABLES TO anon, authenticated, service_role;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres IN SCHEMA "tutorial"
GRANT ALL ON ROUTINES TO anon, authenticated, service_role;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres IN SCHEMA "tutorial"
GRANT ALL ON SEQUENCES TO anon, authenticated, service_role;
-------------------------------------------
-- Create a table called "todos" with a column to store tasks.
create table "tutorial".todos (
id serial primary key,
task text
);
-- Turn on security
alter table "tutorial"."todos" enable row level security;
-- drop policy if exists "Allow anonymous access" on todos;
-- Allow anonymous access (for all = CRUD)
create policy "Allow anonymous access"
on "tutorial".todos -- (for all)
to anon using (true);
insert into "tutorial".todos (task) values
('Create tables'),
('Enable security'),
('Add data'),
('Fetch data from the API');
client 생성시 db.schema 를 지정하면 public 처럼 사용할 수 있다.
1
2
3
4
5
6
7
8
// Initialize the JS client
import { createClient } from '@supabase/supabase-js'
const supabase = createClient(SUPABASE_URL, SUPABASE_ANON_KEY,
{ db: { schema: 'tutorial' } } // supabase-js v2
)
// Make a request
const { data: todos, error } = await supabase.from('todos').select('*')
참고: dblink 사용법
- 연결명 등록 dblink_connect
- 탐색경로(스키마) 지정시 추가
접속정보... options=-csearch_path=
- 탐색경로(스키마) 지정시 추가
- 연결명 조회 dblink_get_connections
- 연결명 해제 dblink_disconnect
- 원격 쿼리 dblink
- 원격 명령(insert/update/delete) dblink_exec
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
CREATE EXTENSION dblink;
-- 연결명 등록
select dblink_connect(
'jnewsdb',
'hostaddr=아이피 port=포트 dbname=데이터베이스 user=사용자 password=패스워드'
);
-- OK
-- 등록된 연결명 조회 (text[])
SELECT dblink_get_connections() as conns;
-- {jnewsdb}
-- 연결명 제거
select dblink_disconnect('jnewsdb');
-- OK
-- 연결 테스트 (원격쿼리에 대한 레코드 정의가 꼭 필요하다)
-- 참고 : 멀티라인 작성시 $$ 부호를 사용
select *
from dblink('jnewsdb', $$
select domain, pub_dt, url, title, content
from jnews.article
limit 2
$$)
as jnews(
domain text,
pub_dt timestamp,
url text,
title text,
content text
);
끝! 읽어주셔서 감사합니다.