형태소 분석기를 이용하여 검색 서비스의 성능을 향상시킬 수 있습니다. 이를 위해 elasticsearch 의 nori 플러그인과 mecab-ko 형태소 분석기에 대해 공부합니다.
- Elasticsearch 작업하기 - 1일차 : es, kibana 설치
- Elasticsearch 작업하기 - 2일차 : nori plugin, mecab-co 설치 ✔
1. ES 클러스터 도커 설치
1일차 작업 이후, 결국 도커로 멀티 노드 클러스터로 재설치하였다. 샤딩을 통해 탐색 성능도 높이고, 시스템 효율성도 높이기 위해 공식문서의 node 3개짜리 Docker 샘플을 수정하여 적용하였다.
1) Dockerfile
기본 es 이미지에 nori 플러그인과 icu 플러그인을 추가했다.
1
2
3
4
5
6
7
8
9
ARG build_ver=8.7.0
FROM docker.elastic.co/elasticsearch/elasticsearch:${build_ver}
# plugins
RUN /usr/share/elasticsearch/bin/elasticsearch-plugin install \
--batch analysis-icu
RUN /usr/share/elasticsearch/bin/elasticsearch-plugin install \
--batch analysis-nori
elasticsearch-jaso-analyzer 도 설치하고 싶었지만, 버전이 달라 설치할 수 없었다. (latest = 8.6.2)
1
2
3
4
5
# BUILD
$ docker build -t elasticsearch-with-nori .
# 또는 버전
# docker build --build-arg build_ver=8.7.0 -t elasticsearch-with-nori .
2) docker-compose.yml
플러그인이 추가된 이미지 elasticsearch-with-nori 를 이용해 es 노드들을 실행시킨다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
version: "2.2"
services:
setup:
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
container_name: es_setup
volumes:
- certs_data:/usr/share/elasticsearch/config/certs
user: "0"
command: >
bash -c '
if [ x${ELASTIC_PASSWORD} == x ]; then
echo "Set the ELASTIC_PASSWORD environment variable in the .env file";
exit 1;
elif [ x${KIBANA_PASSWORD} == x ]; then
echo "Set the KIBANA_PASSWORD environment variable in the .env file";
exit 1;
fi;
if [ ! -f config/certs/ca.zip ]; then
echo "Creating CA";
bin/elasticsearch-certutil ca --silent --pem -out config/certs/ca.zip;
unzip config/certs/ca.zip -d config/certs;
fi;
if [ ! -f config/certs/certs.zip ]; then
echo "Creating certs";
echo -ne \
"instances:\n"\
" - name: es01\n"\
" dns:\n"\
" - es01\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
" - name: es02\n"\
" dns:\n"\
" - es02\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
" - name: es03\n"\
" dns:\n"\
" - es03\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
> config/certs/instances.yml;
bin/elasticsearch-certutil cert --silent --pem -out config/certs/certs.zip --in config/certs/instances.yml --ca-cert config/certs/ca/ca.crt --ca-key config/certs/ca/ca.key;
unzip config/certs/certs.zip -d config/certs;
fi;
echo "Setting file permissions"
chown -R root:root config/certs;
find . -type d -exec chmod 750 \{\} \;;
find . -type f -exec chmod 640 \{\} \;;
echo "Waiting for Elasticsearch availability";
until curl -s --cacert config/certs/ca/ca.crt https://es01:9200 | grep -q "missing authentication credentials"; do sleep 30; done;
echo "Setting kibana_system password";
until curl -s -X POST --cacert config/certs/ca/ca.crt -u "elastic:${ELASTIC_PASSWORD}" -H "Content-Type: application/json" https://es01:9200/_security/user/kibana_system/_password -d "{\"password\":\"${KIBANA_PASSWORD}\"}" | grep -q "^{}"; do sleep 10; done;
echo "All done!";
'
healthcheck:
test: ["CMD-SHELL", "[ -f config/certs/es01/es01.crt ]"]
interval: 1s
timeout: 5s
retries: 120
es01:
restart: always
depends_on:
setup:
condition: service_healthy
# image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
image: elasticsearch-with-nori:latest
container_name: esnode01
volumes:
- ./user_dic:/usr/share/elasticsearch/config/user_dic
- certs_data:/usr/share/elasticsearch/config/certs
- es01_data:/usr/share/elasticsearch/data
ports:
- ${ES_PORT}:9200
environment:
- node.name=es01
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es02,es03
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es01/es01.key
- xpack.security.http.ssl.certificate=certs/es01/es01.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es01/es01.key
- xpack.security.transport.ssl.certificate=certs/es01/es01.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
mem_limit: ${MEM_LIMIT_2G}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test:
[
"CMD-SHELL",
"curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'",
]
interval: 10s
timeout: 10s
retries: 120
es02:
restart: always
depends_on:
- es01
# image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
image: elasticsearch-with-nori:latest
container_name: esnode02
volumes:
- ./user_dic:/usr/share/elasticsearch/config/user_dic
- certs_data:/usr/share/elasticsearch/config/certs
- es02_data:/usr/share/elasticsearch/data
environment:
- node.name=es02
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es01,es03
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es02/es02.key
- xpack.security.http.ssl.certificate=certs/es02/es02.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es02/es02.key
- xpack.security.transport.ssl.certificate=certs/es02/es02.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
mem_limit: ${MEM_LIMIT_2G}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test:
[
"CMD-SHELL",
"curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'",
]
interval: 10s
timeout: 10s
retries: 120
es03:
restart: always
depends_on:
- es02
# image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
image: elasticsearch-with-nori:latest
container_name: esnode03
volumes:
- ./user_dic:/usr/share/elasticsearch/config/user_dic
- certs_data:/usr/share/elasticsearch/config/certs
- es03_data:/usr/share/elasticsearch/data
environment:
- node.name=es03
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es01,es02
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es03/es03.key
- xpack.security.http.ssl.certificate=certs/es03/es03.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es03/es03.key
- xpack.security.transport.ssl.certificate=certs/es03/es03.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
mem_limit: ${MEM_LIMIT_2G}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test:
[
"CMD-SHELL",
"curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'",
]
interval: 10s
timeout: 10s
retries: 120
kibana:
restart: always
depends_on:
es01:
condition: service_healthy
es02:
condition: service_healthy
es03:
condition: service_healthy
image: docker.elastic.co/kibana/kibana:${STACK_VERSION}
container_name: kibana
volumes:
- certs_data:/usr/share/kibana/config/certs
- kibana_data:/usr/share/kibana/data
ports:
- ${KIBANA_PORT}:5601
environment:
- SERVERNAME=kibana
- ELASTICSEARCH_HOSTS=https://es01:9200
- ELASTICSEARCH_USERNAME=kibana_system
- ELASTICSEARCH_PASSWORD=${KIBANA_PASSWORD}
- ELASTICSEARCH_SSL_CERTIFICATEAUTHORITIES=config/certs/ca/ca.crt
mem_limit: ${MEM_LIMIT_500M}
cpus: 0.5
healthcheck:
test:
[
"CMD-SHELL",
"curl -s -I http://localhost:5601 | grep -q 'HTTP/1.1 302 Found'",
]
interval: 10s
timeout: 10s
retries: 120
volumes:
certs_data:
driver: local
driver_opts:
o: bind
type: none
device: ${ES_DATA_ROOT}/certs
es01_data:
driver: local
driver_opts:
o: bind
type: none
device: ${ES_DATA_ROOT}/es01
es02_data:
driver: local
driver_opts:
o: bind
type: none
device: ${ES_DATA_ROOT}/es02
es03_data:
driver: local
driver_opts:
o: bind
type: none
device: ${ES_DATA_ROOT}/es03
kibana_data:
driver: local
driver_opts:
o: bind
type: none
device: ${ES_DATA_ROOT}/kibana
변경사항
- mem_limit: MEM_LIMIT_1G (~ _4G)
- kibana 는 최대 500M 메모리와 cpus=0.5 를 배정했다
- restart 추가 : es01, es02, es03, kibana
- always 옵션으로 재부팅시에 자동 재시작이 되도록 설정
- volumes 연결 : certs, kibana, es01, es02, es03
- nori 의 사용자 사전
userdict_ko.txt도 연결
- nori 의 사용자 사전
설정했다가 취소한 사항들
- es_nodes 에 build 항목으로 Dockerfile 연결했더니, 스택이 실행되면서 제각각 이미지가 생겨버렸다.
- “ES_JAVA_OPTS=-Xms1G -Xmx1G” 설정을 추가했는데, 시동 실패
- 최대 메모리를 설정한 상태에서 영향을 받은 모양이다.
3) 실행, 중지
1
2
3
4
5
6
7
8
# 실행
$ docker compose up -d
# 중지되면 자원이 해제된 상태라 재시작 되지 않는다.
$ docker compose down
# 자원이 해제되고 삭제된다 (local 데이터는 남는다)
$ docker compose down -v
도커 스택이 down 되지 않았다면, 서버 재시동시 재시작 된다.
2. nori analysis plugin
Elasticsearch 는 한국어 분석을 위해 mecab-ko 형태소 분석기를 제공하고 있다.
참고문서
1) nori plugin 설치
도커에서는 이미지에 추가한 상태라 아래 단계가 필요 없지만, 설명을 위해 작성한다.
1
2
3
$ sudo bin/elasticsearch-plugin install analysis-nori
$ sudo systemctl restart elasticsearch
2) nori tokenizer 테스트
한국어 형태소 분석기는 문장을 문장 성분 단위로 단어들을 분리하기 위해 필요하다. 조사를 분리하고 복합명사를 쪼개어 매칭되도록 만들기 위해서 nori tokenizer 와 nori filter 를 사용한다.
- analyzer 는 tokenizer 와 filter 의 조합이다.
standard analyzer (비교를 위해 작성)
기본적으로 사용되는 분석기이며, 공백과 문장부호로 토큰을 분리하여 출력한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
GET /_analyze
{
"analyzer": "standard",
"text": ["동해물이 세종시에 다다르고, 넘치도록!"]
}
# 출력
{
"tokens": [
{
"token": "동해물이",
"start_offset": 0,
"end_offset": 4,
"type": "<HANGUL>",
"position": 0
},
{
"token": "세종시에",
"start_offset": 5,
"end_offset": 9,
"type": "<HANGUL>",
"position": 1
},
{
"token": "다다르고",
"start_offset": 10,
"end_offset": 14,
"type": "<HANGUL>",
"position": 2
},
{
"token": "넘치도록",
"start_offset": 16,
"end_offset": 20,
"type": "<HANGUL>",
"position": 3
}
]
}
nori analyzer
세종시 를 종시 로 오분석하고 있다. 가산명사(MM) 세를 누락시켰다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
GET /_analyze
{
"analyzer": "nori",
"text": ["동해물이 세종시에 다다르고, 넘치도록!"]
}
# 출력
{
"tokens": [
{
"token": "동해",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "물",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "종시",
"start_offset": 6,
"end_offset": 8,
"type": "word",
"position": 4
},
{
"token": "다르",
"start_offset": 11,
"end_offset": 13,
"type": "word",
"position": 7
},
{
"token": "넘치",
"start_offset": 16,
"end_offset": 18,
"type": "word",
"position": 9
}
]
}
# mecab 실행 결과 (nori 와 비교)
$ mecab "세종시에 이르렀다""
세 MM,~가산명사,F,세,*,*,*,*
종시 NNG,*,F,종시,*,*,*,*
에 JKB,*,F,에,*,*,*,*
이르 VV,*,F,이르,*,*,*,*
렀다 UNKNOWN,*,*,*,*,*,*,*
EOF
nori custom analyzer + 사용자 사전
세종시를 한단어로 인식시키기 위해 사용자 사전(userdict_ko.txt)을 이용했다.- 원하는 품사만 누락시키기 위해 nori_part_of_speech 로 filter 를 정의했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
$ sudo cat <<EOF > /etc/elasticsearch/userdict_ko.txt
세종시 세종 시
EOF
GET /_analyze
{
"tokenizer": {
"type" : "nori_tokenizer",
"decompound_mode": "none",
"discard_punctuation": "true",
"user_dictionary": "user_dic/nori_ko.txt"
},
"filter": {
"type" : "nori_part_of_speech",
"stoptags" : [
"E","IC","J","MAG","MAJ","MM","NP",
"SP","SSC","SSO","SC","SE",
"XPN","XSA","XSV","UNA","NA",
"VCN","VCP","VV","VX","VSV"
]
},
"text": ["동해물이 세종시에 다다르고, 넘치도록!"]
}
# 출력
{
"tokens": [
{
"token": "동해물",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0,
"positionLength": 2
},
{
"token": "동해",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "물",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "세종시",
"start_offset": 5,
"end_offset": 8,
"type": "word",
"position": 3,
"positionLength": 2
},
{
"token": "세종",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 3
},
{
"token": "시",
"start_offset": 7,
"end_offset": 8,
"type": "word",
"position": 4
},
{
"token": "다르",
"start_offset": 11,
"end_offset": 13,
"type": "word",
"position": 7
}
]
}
3) 동의어(synonym) 테스트
동의어 사전을 참조해 토큰을 확장, 대체한다. 중복된 토큰은 remove_duplicates으로 제거한다.
참고문서
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
GET /_analyze
{
"tokenizer": {
"type" : "nori_tokenizer",
"decompound_mode": "none",
"discard_punctuation": "true",
"user_dictionary": "user_dic/nori_ko.txt"
},
"filter": [
{
"type" : "nori_part_of_speech",
"stoptags" : [
"E","IC","J","MAG","MAJ","MM","NP",
"SP","SSC","SSO","SC","SE",
"XPN","XSA","XSV","UNA","NA",
"VCN","VCP","VV","VX","VSV"
]
},
{
"type": "synonym",
"synonyms": [
"universe , cosmos",
"i-pod, i pod => 아이팟",
"동해물 => 동해바닷물, 동해바다"
]
},
{
"type": "remove_duplicates"
}
],
"text": ["동해물이 세종시에 이르고, i-pod가 universe에 넘치도록!"]
}
# 출력
{
"tokens": [
{
"token": "동해",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 0
},
{
"token": "바닷물",
"start_offset": 2,
"end_offset": 3,
"type": "SYNONYM",
"position": 1
},
{
"token": "바다",
"start_offset": 2,
"end_offset": 3,
"type": "SYNONYM",
"position": 1
},
{
"token": "세종시",
"start_offset": 5,
"end_offset": 8,
"type": "word",
"position": 3
},
{
"token": "아이팟",
"start_offset": 15,
"end_offset": 20,
"type": "SYNONYM",
"position": 4
},
{
"token": "universe",
"start_offset": 22,
"end_offset": 30,
"type": "word",
"position": 6
},
{
"token": "cosmos",
"start_offset": 22,
"end_offset": 30,
"type": "SYNONYM",
"position": 6
}
]
}
주의사항: 동의어에 의해 token 의 개수가 변경되면 안된다. position 이 밀리는 문제가 발생하면 analyzer 오류 발생
i-pod을아이팟으로 변경하면서아이+팟으로 분리가 되면, 토큰의 포지션이 틀려지게 됨- 해결 : nori 사용자 사전에
아이팟을 추가하여 단일 토큰으로 처리되도록 함
3. 형태소 분석기 macab 설치
패턴 매칭으로 품사를 분류하고, 사용자 사전을 통해 단어와 태그를 추가할 수 있다.
1) mecab-ko 및 mecab-ko-dic 설치
두개의 모듈을 설치하여야 한다. 하나는 mecab 분석기, 또 하나는 mecab 사전이다.
인텔 버전 Mac Mini 대상으로 다음과 같이 설치했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# mecab-ko 설치
$ wget "https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz"
$ tar xvfz mecab-0.996-ko-0.9.2.tar.gz
$ cd mecab-0.996-ko-0.9.2
$ ./configure
$ make
$ make check
$ sudo make install
# 확인
$ mecab --version
mecab of 0.996/ko-0.9.2
# mecab-ko-dic 설치
$ wget "https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.1.1-20180720.tar.gz"
$ tar xvfz mecab-ko-dic-2.1.1-20180720.tar.gz
$ cd mecab-ko-dic-2.1.1-20180720
$ ./configure
$ make
$ sudo make install
# 테스트 (-d 는 사전위치 옵션: 없어도 됨)
$ echo '설치가 완료되었습니다.' | mecab -d /usr/local/lib/mecab/dic/mecab-ko-dic
설치 NNG,행위,F,설치,*,*,*,*
가 JKS,*,F,가,*,*,*,*
완료 NNG,행위,F,완료,*,*,*,*
되 XSV,*,F,되,*,*,*,*
었 EP,*,T,었,*,*,*,*
습니다 EF,*,F,습니다,*,*,*,*
. SF,*,*,*,*,*,*,*
EOS
2) 품사 태그
원문 링크: mecab-ko-dic 품사 태그 설명
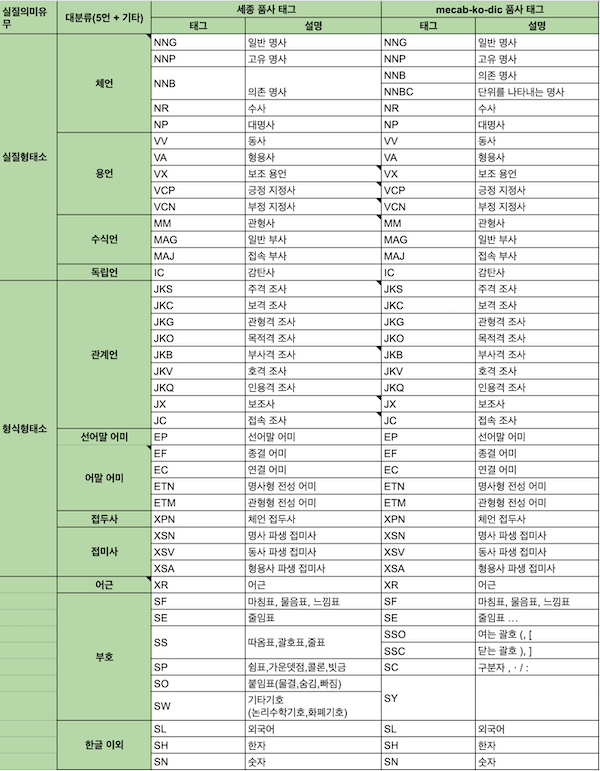 mecab 사전 품사 태그
mecab 사전 품사 태그
3) 사용자 사전 추가
추가 조사가 필요하여 다음 작업에서 기술하겠다.
9. Review
- 돌고 돌아 도커로 설정했다. 리눅스+도커 조합이 짱이다.
- 맥북은 개발하는데나 사용하자
- ChatGPT 시대에 왠 검색이고 형태소 분석기냐 하겠지만, 아직도 대다수 서비스에 쓰이는 검증된 기술이다.
- 시맨틱 검색으로 가자!
참고자료
끝! 읽어주셔서 감사합니다.