[알림] 본 연구는 “2019 GCS 창업성장과제” 의 지원으로 진행된 “그래프 기술 기반 Graph AI 솔루션 연구개발” 과제의 연구결과입니다. AgensKG의 모든 저작권은 비트나인에 있습니다.
지식그래프 AgensKG
왜 그래프 기반 지식그래프인가?
테이블과 그래프는 데이터 저장 구조의 메커니즘이 서로 다르기 때문에 각각 장단점을 가집니다. 테이블은 동일한 관계 전체를 빠르게 처리하는 특성이 있으며, 그래프는 어떤 위치의 node에서라도 동일한 방식으로 edge가 연결된 node들를 탐색해 나가며 데이터를 처리합니다. 때문에 데이터의 확장과 접근이 자유롭고 관계에 대한 연산이 가능합니다. 이러한 메커니즘은 데이터 처리의 유연성을 제공하며 지식그래프와 같은 유형에 적합합니다.
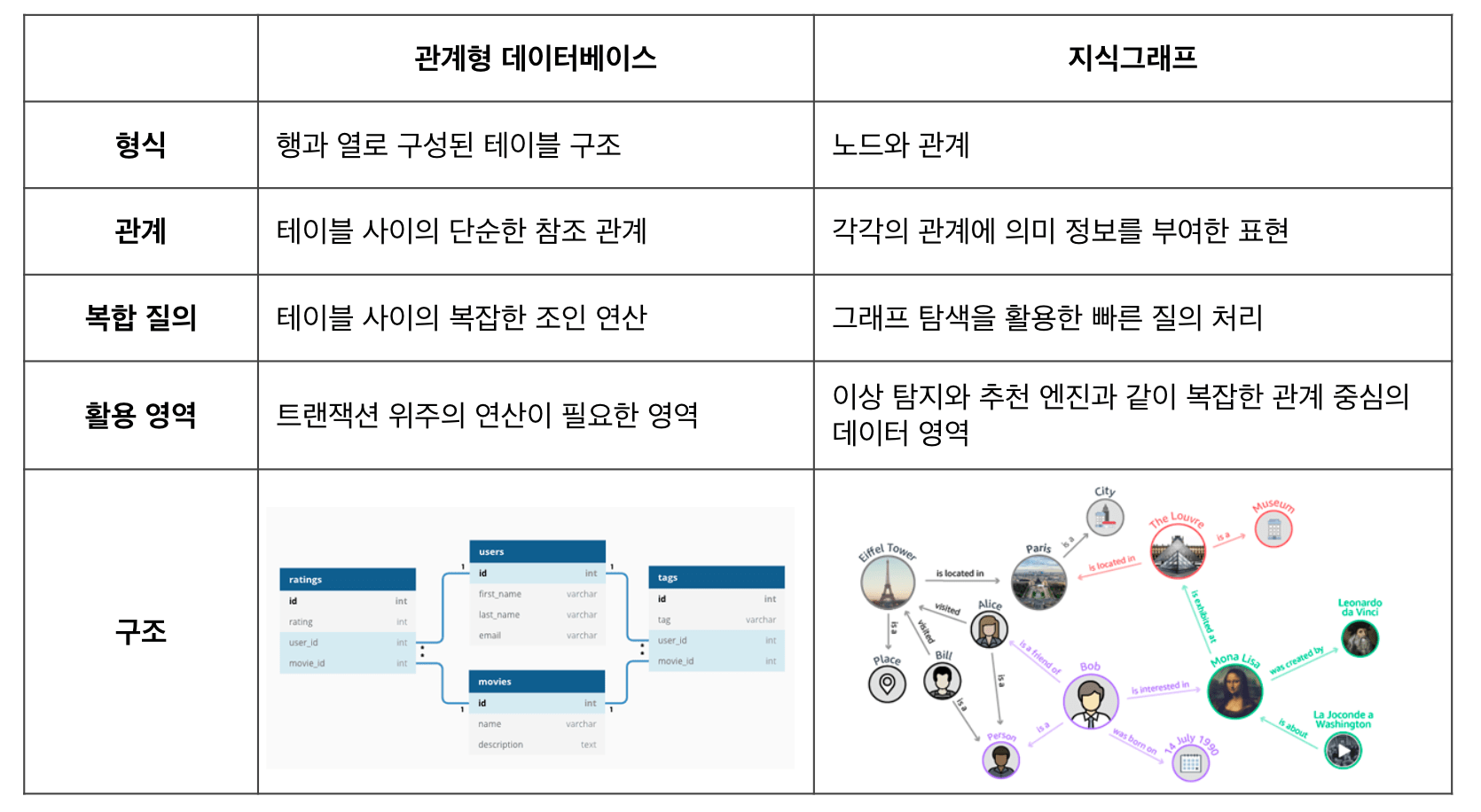
<그림> 관계형 DB와 지식그래프 비교
차별성 및 독창성
AgensKG는 최근에 널리 사용되고 있는 딥러닝 방식의 블랙박스 형태의 지식모델과 다른 방식으로 구현되었습니다. 지식의 원천인 원본 텍스트의 내용이 올바르다는 가정하에 자연어의 문법적인 구조를 의미 관계로 변형하여 지식그래프를 생성합니다. 생성된 관계는 시각적으로 사람이 보고 이해할 수 있으며, 수정 가능해서 이와 연결된 딥러닝 방식의 단어 모델과 함께 질의응답 기능을 제공합니다.
AgensKG가 다른 지식그래프 구현체와 다른 독창성은 다음과 같습니다.
가. 확장성 있는 지식 모델링
방대한 텍스트 데이터를 지식그래프를 저장하는데 있어서 토픽 구분을 자유롭게 만들어 다양한 지식을 저장할 수 있도록 지식 모델을 설계했습니다. SUMMARY는 하나의 토픽을 대표하는 최상위 지식 개체이고 여러 키워드의 묶음으로 구별됩니다. 이를 통해 하나의 주제에 대해서도 다양한 버전의 토픽이 저장되고 표현될 수 있습니다. 하위에 속한 TRIPLE 그룹은 지식그래프의 실체를 표현하는데, 동일한 내용이라 하더라도 최상위 SUMMARY가 다르면 중복이 가능합니다. 중복되는 TRIPLE 그룹은 이후 질의 과정에서 그래프 알고리즘을 이용해 answer 함수가 더 적합한 답변을 출력하도록 랭킹과 매칭 전략을 적용하게 됩니다.
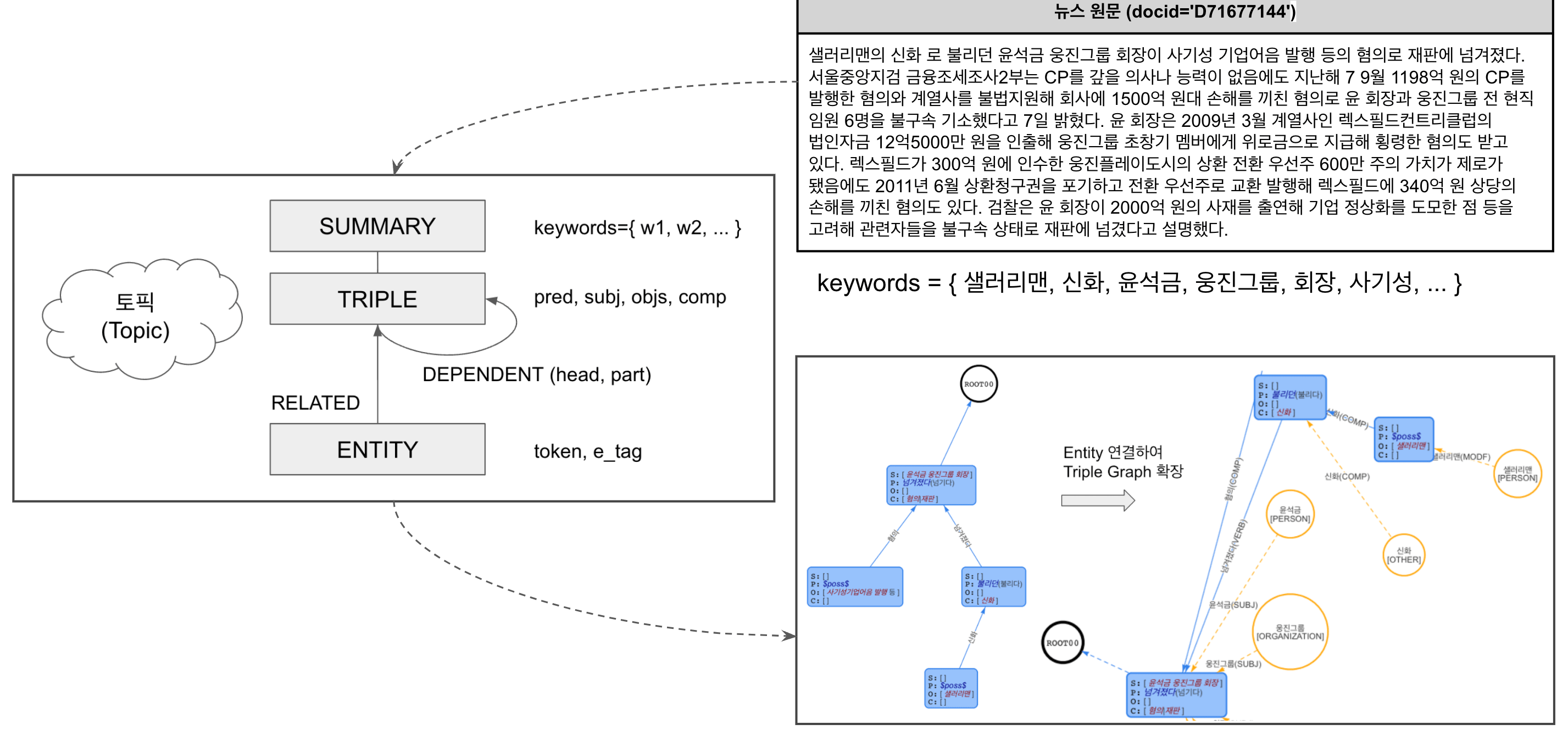
<그림> AgensKG의 지식 모델링
나. 한국어 기반 지식표현
본 연구에서는 한국어의 문장의 구성요소 주어(S), 동사(P), 목적어(O), 보어(C)로 정의하고, 부사어를 모두 보어로 치환시켰습니다. SPOC의 문장구조는 한국어의 모든 유형을 표현할 수 있기 때문에, 한국어 원문으로부터 지식그래프로의 변환도 수월하게 진행할 수 있었습니다. 또한 하나 이상의 목적어나 보어를 하나의 SPOC Triple에 담을 수 있도록 했습니다. <그림>은 한국어 문장 “영미는 준호를 천재로 여긴다”를 SPOC 구조로 변환한 예시입니다.
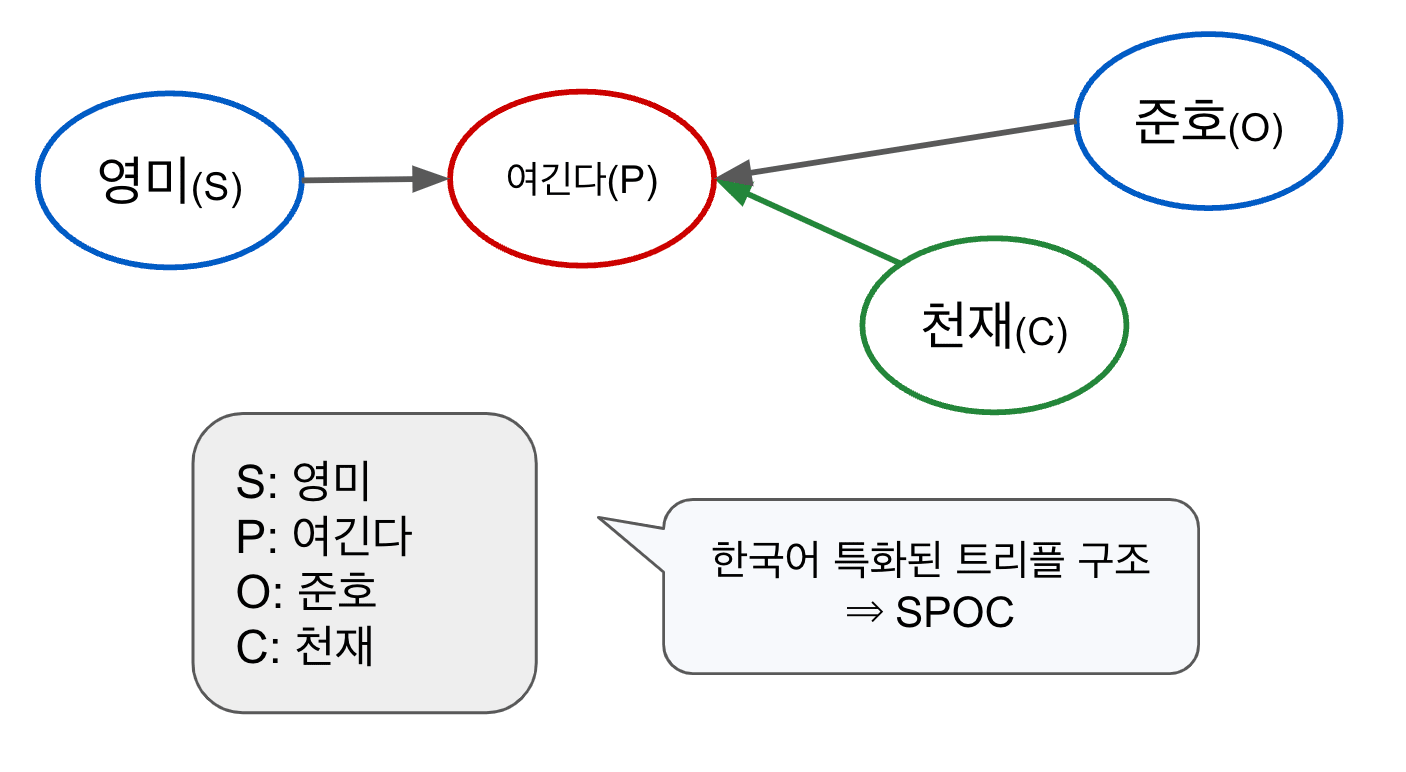
<그림> 한국어에 특화된 트리플(SPOC)의 시각화 예시
다. 복합한 문장구조와 서술어 의문 유형도 처리
기존 연구에서는 일부 복합형 질문을 제외하면 주어와 동사가 하나인 단일형 문장에 대한 질의만 가능하다는 한계점이 있었습니다. 또한 질문의 대상이 문장 구조의 주어 또는 목적어에 제한되는 한계점도 있었습니다. 본 연구에서는 Why를 제외한 1H4W 의문형에 대한 질문을 처리하고, 단일형 문장 외에도 하나 이상의 주어, 서술어가 포함된 복합형 문장의 질문에도 답변할 수 있는 의문문 분석기(Question Analyzer)를 개발하였습니다. 또한 공리(Axiom) 개념을 도입하여 의문사에 포함되지 않아도 토픽(Topic) 매칭에 필요한 키워드를 입력받아 정확한 답변을 할 수 있도록 하였습니다.
| 질문유형 | 질문 | AgensKG 답변 | 설명 |
|---|---|---|---|
| Who | 누구가 현대자동차 울산공장 철탑농성 현장을 방문하는가? | 마가렛세카기야 유엔인권옹호자특별보고관 | 인물, 기관에 매칭 |
| When | 현대자동차 울산공장 철탑농성 현장에 언제방문했는가? | 3일 오전 10시 | 날짜, 시간에 매칭 |
| Howmuch | 가정은 자녀의 양육비로 얼마를 지출하는가? | 평균 118만9000원 | 가격, 단위에 매칭 |
| What | 윤석금 회장은 무슨혐의로 재판에 넘겨졌는가? | 사기성기업어음 발행 등 | 인물 제외 |
| How | 기상청은 6월 기온이 어떠할것으로 예상하는가? | 기온 6월 평년 (월등히 높고) | 서술어에 매칭 |
| Axiom+What | 비산먼지발생사업장에 대한 질문이다. 무엇을 설치했는지 여부를 점검할 예정인가? | 비산먼지발생억제시설 | 공리(Axiom) 포함하여 검색 후 사물 매칭 |
| Axiom+Where | 이라크 폭탄테러에 관한 질문이다. 어디에서 폭탄이 터졌는가? | 알아밀광장 | 공리(Axiom) 포함하여 검색 후 장소에 매칭 |
| Axiom+How | 크로아티아에 관한 질문이다. 한국과의 역대전적이 어떠한가? | 역대전적 2승2무2패 (팽팽하다) | 공리(Axiom) 포함하여 검색 후 서술어 매칭 |
라. 그래프 기반의 빠른 지식 검색
AgensKG에는 약 118만건 뉴스 원문에서 추출한 SPOC Triples 46,032,612 개가 지식그래프 형태로 존재하고 있습니다. NLP로 분석된 단어만 268,711,397개인 빅데이터 크기의 지식그래프를 대상으로 질문 하나를 처리하는데 평균 0.8초의 응답시간을 보입니다. 이처럼 빠른 처리 성능은 그래프 기반의 검색을 채택하고 있기 때문입니다. 질문 문장으로부터 추출한 키워드를 대상으로 토픽과 매칭되는 지식그래프를 검색하고 질문 문장의 그래프와 유사한 구조의 지식그래프를 정렬하는 방식은 기존의 관계형 데이터베이스(RDB)와는 다른 검색 방식을 취합니다. 조인 없이 키워드와 관계되는 서브그래프들을 바로 접근하여 메모리 기반으로 그래프 알고리즘을 수행하기 때문에 빠른 검색이 가능합니다.
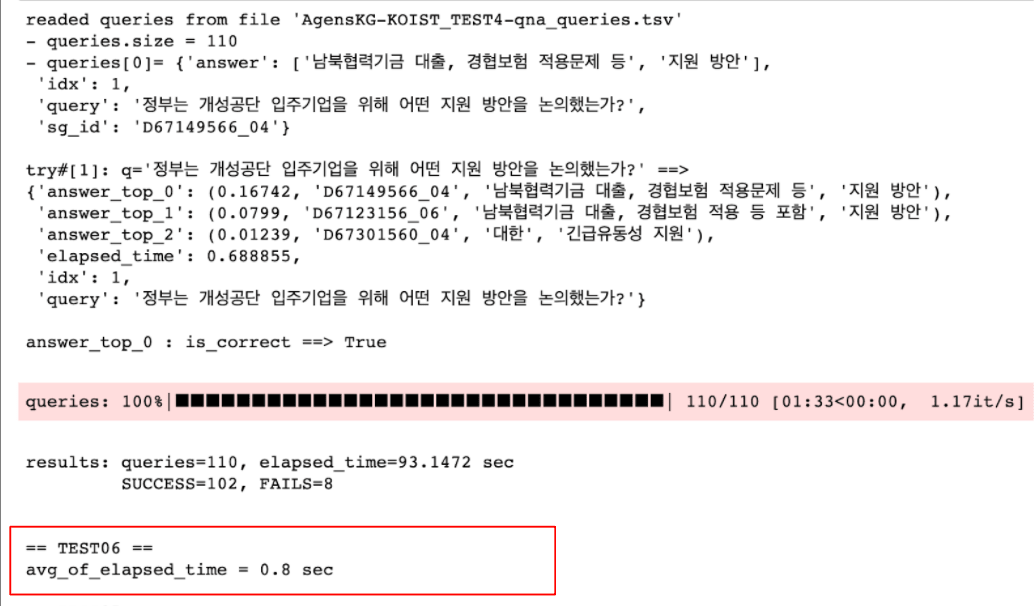
<그림> 질문 문장 110개에 대한 질의응답 API의 평균 응답시간 측정 결과
마. 지식그래프의 시각화
설명 가능한 AI를 위해 질의응답시 결과의 근거를 추론할 수 있도록 시각화 기능을 지원합니다. 사용자의 질의 문장을 의문사를 제외한 서브그래프로 생성하고, 지식그래프와 매칭하여 나온 응답 지식그래프들을 그래프 형태로 도식화하여 출력합니다. 이와 같은 시각화는 각 토픽별 지식그래프에서도 동일하게 적용합니다.
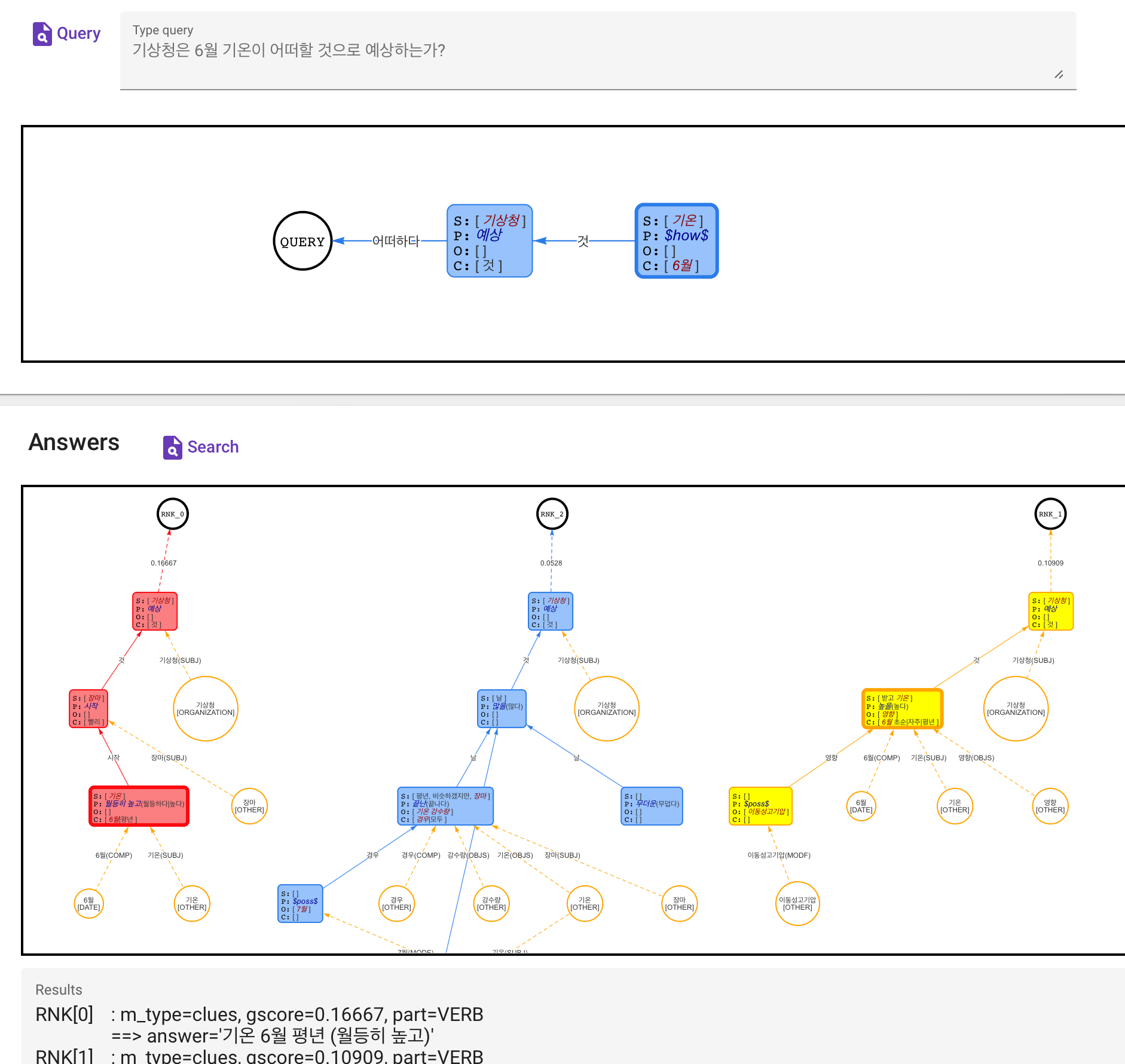
<그림> AgensKG의 질의응답 결과 예시 (질문 그래프와 결과 그래프)
<그림>에서 파란색 네모는 하나의 SPOC Triple을 가리키고, Triple 간에는 Joint 정보와 함께 간선으로 연결됩니다. 주황색의 원은 Triple에 연관된 개체(Entity)를 의미하고, Triple과 개체 간에도 Joint 정보와 함께 간선으로 연결되어 출력됩니다. 응답 지식그래프는 정답을 가리키는 Triple을 강조하기 위해 외곽선을 두껍게 하여 시인성을 높였습니다. 각 응답 그래프의 ROOT 노드는 Answer 함수의 점수와 순위를 함께 표시합니다.
그 외 데이터 분석
그래프AI 솔루션 개발을 위해 자연어 텍스트로 이루어진 빅데이터를 해석하고 다루기 위한 목적으로 여러 데이터 분석기능을 함께 개발하였습니다. 단어의 출현 통계와 중요도 선별을 위해 TFIDF 가중치를 생성했고, 유사한 문서들을 그룹핑하고 변별성을 살펴보기 위해 Doc2Vec 기반의 유사문서 검색기능을 개발하였습니다. 원문 내에서 대표 문장을 선별하기 위해 TextRank를 이용해 대표 문장을 시각화하는 기능도 추가하였습니다.
○ SPARK 기반 TFIDF 분석
뉴스 원문 약 118만건으로부터 NLP로 추출된 단어만 2억6870만건으로 일반적인 메모리 기반으로 처리하기 어려운 빅데이터이기 때문에 Spark기반으로 TFIDF를 계산하는 기능을 개발하였습니다.
○ Doc2Vec 기반 유사문서 검색 및 클러스터링
하나의 이슈에 대해 비슷한 내용의 뉴스 원문이 다수 존재하기 때문에 데이터 인사이트를 제공하기 위한 도구로 유사문서를 검색하는 기능을 구현하였습니다. Doc2Vec은 Word2Vec에서 확장된 알고리즘으로 문장 단위의 벡터로 문서간의 유사성을 판별합니다. 유사문서집합을 주성분분석 PCA를 이용해 2차원으로 분리하고 XY차트 상에 출력하고, K-means와 DBScan 클러스터링 알고리즘으로 문서집합을 구분지어 볼 수 있도록 구현하였습니다.
○ TextRank 이용한 대표 문장 선정
TextRank는 PageRank에서 응용된 알고리즘으로 문서를 단어 그래프로 구성하고 핵심단어와 핵심단어의 참조를 많이 받는 문장을 선별하는 방식으로 학심 문장을 선택합니다. 시각화를 통해 문서 내에서 핵심문장을 쉽게 구별하여 볼수 있도록 구현하였습니다.

<그림> 그래프AI 솔루션의 데이터 분석 기능들 (상단:유사문서, 하좌:TextRank, 하우:TFIDF)
지식그래프 생성 규칙 분석 및 적용
지식그래프를 생성하기 위한 의존관계에 대한 분석에는 그래프 쿼리를 이용한 탐색적 분석이 사용됩니다. 자연어의 문법적 구조를 대규모 데이터를 통해 딥러닝으로 모델을 생성해도 되겠지만, 설명 가능하고 투명성이 보장된 단순한 규칙을 사용하기 위해서는 우선적으로 휴리스틱한 접근방법이 사용하는게 적합합니다.
의존관계 분석 전용 Silo (의존그래프 DB)
자연어 분석(NLP)의 결과를 별도의 분석 전용 AgensGraph 그래프DB에 담아 그래프 전용 쿼리인 Cypher 언어로 의존관계를 질의하고 탐색할 수 있습니다. 탐색에 의해 발견된 규칙들은 python 코드로 변환하여 지식그래프를 생성하는 Rule로 사용됩니다. 의존관계를 가공하기 위해 정의된 Rule들은 지식그래프 생성 프로세스에서 실데이터를 대상으로 활용됩니다.
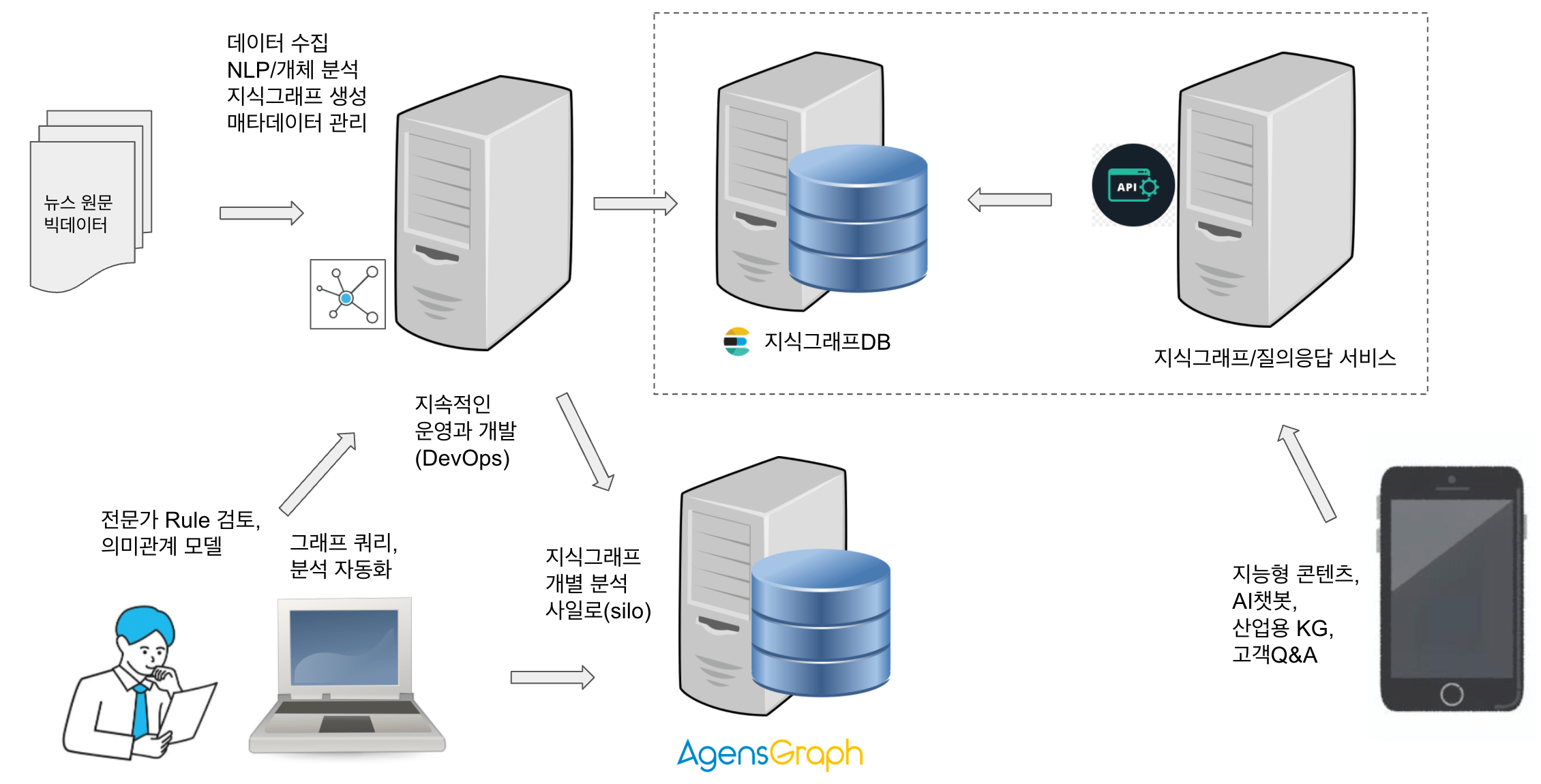
<그림> 의존관계 분석을 위한 그래프DB
Cypher 쿼리를 이용한 의존관계 탐색 및 분석
샘플 성격의 의존관계를 Cypher 쿼리를 통해 뽑아보고, 어떠한 문장 성분으로 추출할 수 있는지를 Cypher 쿼리로 뽑아서 확인합니다. 그림에서 보이는 예시는 “누가 재판에 넘겨졌는지”를 추출하고, “웅진그룹 회장”이 재판에 넘겨진 혐의를 추출하는 쿼리를 재차 실행해 보는 과정을 설명합니다.
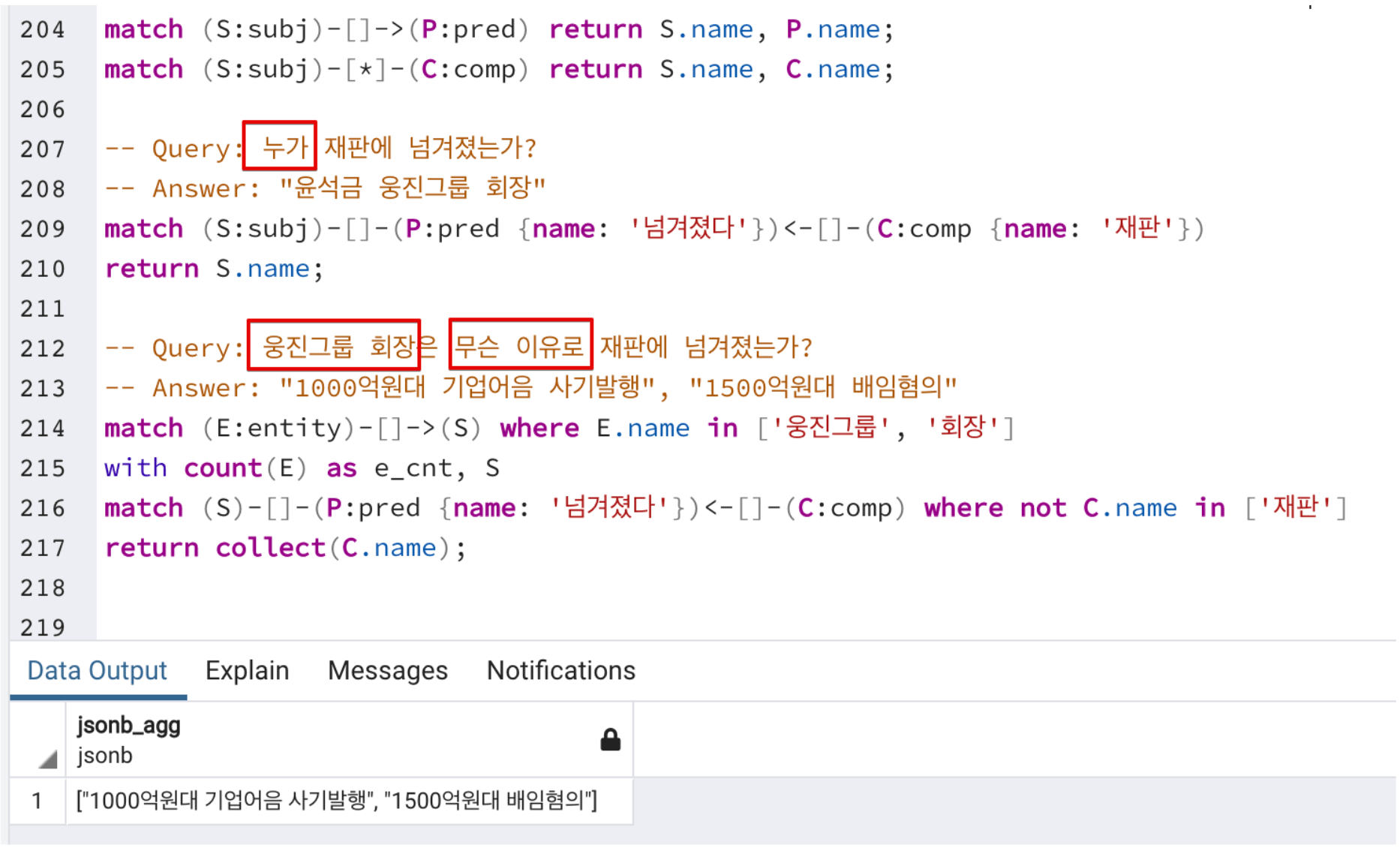
<그림> Cypher 쿼리를 이용한 의존관계 탐색 및 분석
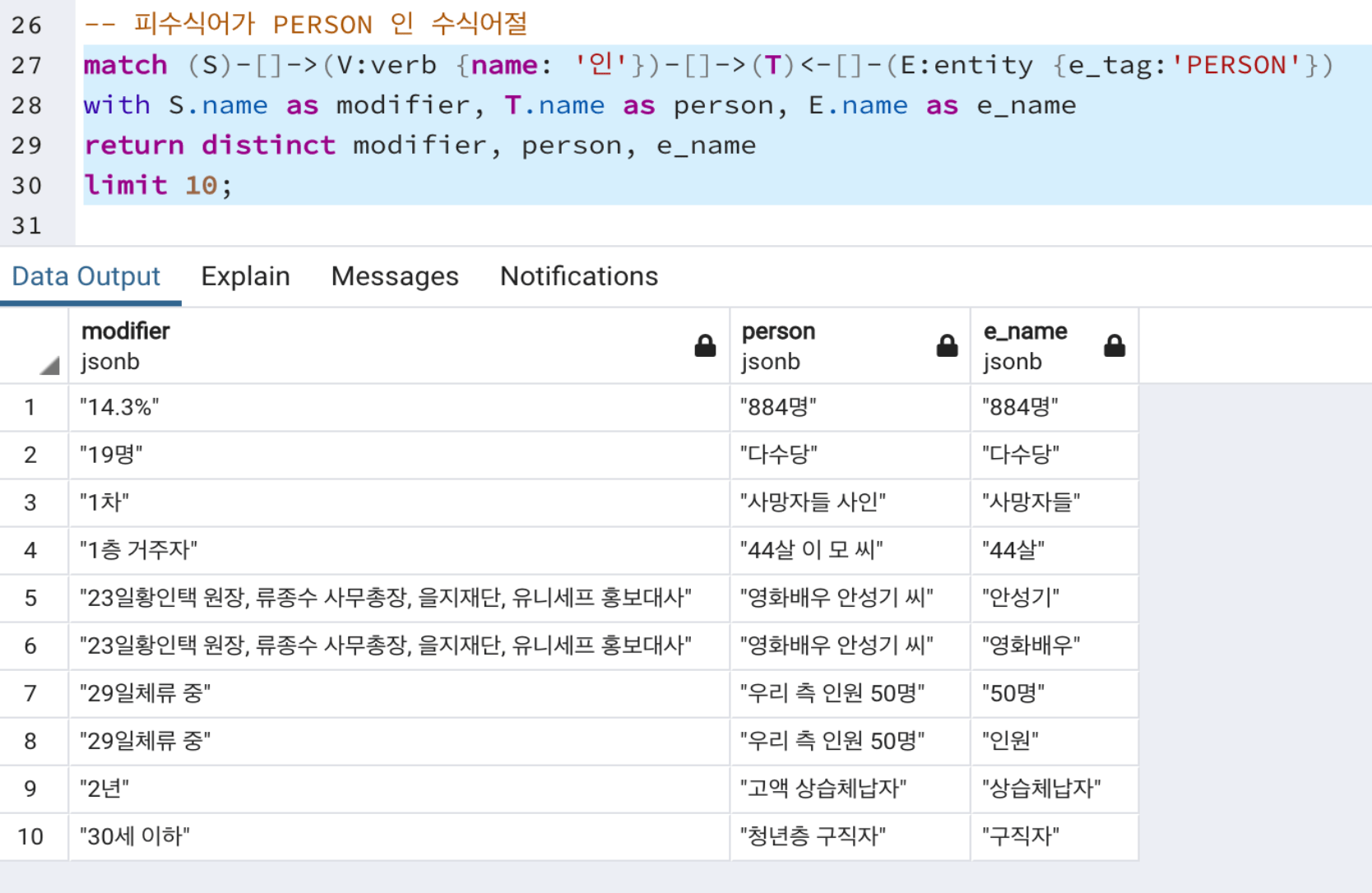
뉴스 텍스트의 경우 “~의 ~” 또는 “~등 ~”와 같은 소유격 또는 동격의 의존관계가 빈번하게 나타납니다. 이를 Entity(개체) 타입과 연결시켜 쿼리하면 비교적 한정적이고 구체화된 의존관계 패턴을 발견할 수 있습니다. 이처럼 발견된 의존관계를 정립하여 지식그래프 생성을 위한 Rule로 활용합니다.
AgensKG 지식그래프 이용시 기대 효과
1) 산업용 KG 활용에 대한 기대 효과
대부분의 기업들은 자사의 제품에 대한 고객게시판을 제공하고 매뉴얼과 FAQ 등의 서비스를 제공하고 있습니다. FAQ는 서비스 매니저가 고객의 불만사항을 수작업으로 작성하기 때문에, 제품의 변화에 대응하여 빠르게 업데이트하지 못합니다. 지식그래프는 고객의 불만사항에 대한 텍스트로부터 지식을 추출하고 문제해결을 위한 지식모델에 통합할 수 있습니다. 지식그래프를 이용한 제품의 지식관리는 소수의 전문가에 의한 지식 체계화보다 효율적이고 빠른 업데이트를 가능하게 합니다.
2) AI챗봇 및 지능형 검색으로의 기대 효과
현재의 AI챗봇은 대화 스크립트를 이용하거나 사람의 대화를 학습하여 흉내내는 방식으로 개발되고 있습니다. 이는 실제 지능을 지닌 것이 아닌 지능을 흉내내는 방식이기 때문에 사용자가 원하는 지식전달 측면의 기능은 부족합니다. 지능형 검색에서도 텍스트 매칭 방식의 문서셋 전달보다 직접적인 답변 방식으로의 정보전달 형태로 발전하고 있습니다. 지식그래프는 지식의 표현과 저장, 활용 측면에서 핵심 엔진의 역활을 수행할 수 있습니다.
3) 설명 가능한 AI(XAI)로서의 효과
머신러닝과 딥러닝 방식은 예측과 분류에 있어서 결과에 대한 이유를 설명하기 어렵습니다. 블랙박스라고 표현되는 복잡한 알고리즘은 전문가만이 조절할 수 있기 때문에 사용자에게 투명성을 제공하기 어렵습니다. 방대한 이종의 데이터를 결합할수록 지식간의 연계성은 복잡해지고 확장을 위한 유지관리의 어려움도 증가합니다. 시각화와 결합된 지식그래프는 지식 검색과 추론에 있어서 사용자에게 투명성을 제공하고, 오류 발견이 쉽습니다.
4) 공공데이터 활성화 측면의 기대 효과
공공데이터의 항목이나 데이터 형식의 표준화 미흡은 데이터 활용에 장애 요소로 지적되고 있습니다. 예를 들어 일선 행정기관의 데이터와 행정자치부에서 관리하는 주소, 전화번호 등에 대한 데이터가 다른 경우 민원인의 입장에서 데이터 품질에 대한 믿지 못하게 됩니다. 기관 코드 중심의 데이터 정렬이 적용되지 못하는 공개 데이터 자체를 연계시키고 하나의 지식그래프로 통합할 수 있다면, 공공데이터의 품질과 활용성이 크게 향상될 수 있습니다.
본 연구에 대한 포스트는 태주네 블로그에 연재됩니다.
끝! 읽어주셔서 감사합니다.