효과적인 그래프 분석을 위해 산만하게 형성된 의존그래프를 가지치기 하는 전처리 작업에 대해 설명합니다.
그래프 분석을 위해 뉴스 기사를 NLP 분석하여 의존그래프를 생성하였다. 전처리가 잘 된 그래프는 그래프 분석시 성능을 높이고 오류를 줄여준다. 그중 필수적인 전처리 작업으로 가지치기(pruning) 작업에 대해 소개한다.
의존그래프는 자연어의 문법적 관계를 그래프로 표현한 것인데, NLP 라이브러리에 따라 결과가 서로 다르다. 특히나 한국어의 경우 교착어 특성으로 토큰 위치에 영향을 받지 않고 조사의 경우 여러 용도로 혼용되는 경우가 있어 정확한 결과를 얻기는 어렵다. 다만, 단순한 문장일수록 또는 문장의 root 로부터 가까울수록 비교적 정확한 결과를 얻을 수 있어 사용가치는 충분하다.
 |
|---|
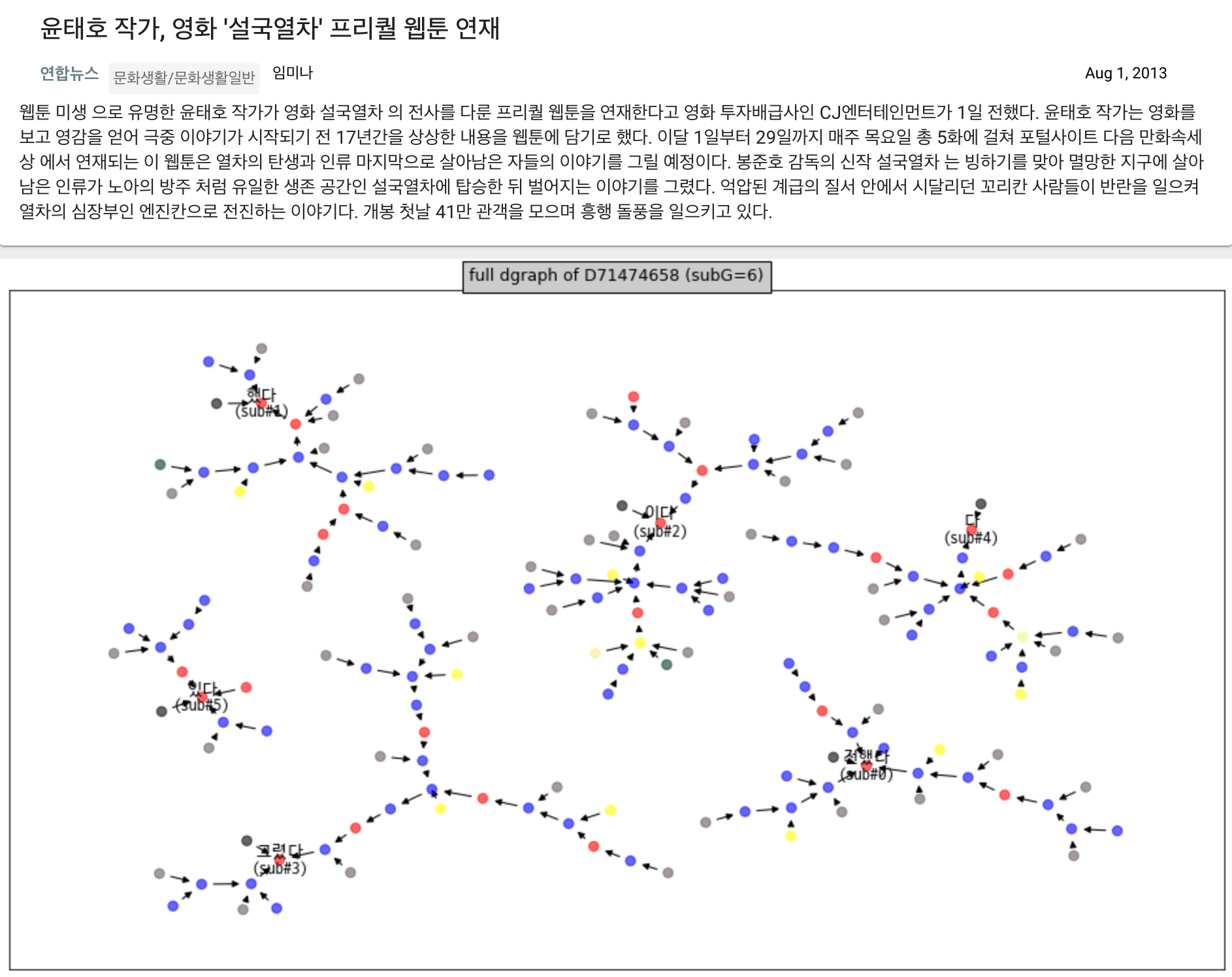
| <그림> 뉴스 샘플 - 문서 의존그래프 (문장 6개) |
뉴스 샘플은 6개의 문장으로 구성되어 있고, 의존그래프의 전체 모습은 다음과 같다. 파란점은 명사(NOUN)이고 빨간점은 동사(VERB)이다. 그 외의 색은 형용사, 부사, 조사 등의 형태소 타입을 의미한다.
 |
|---|
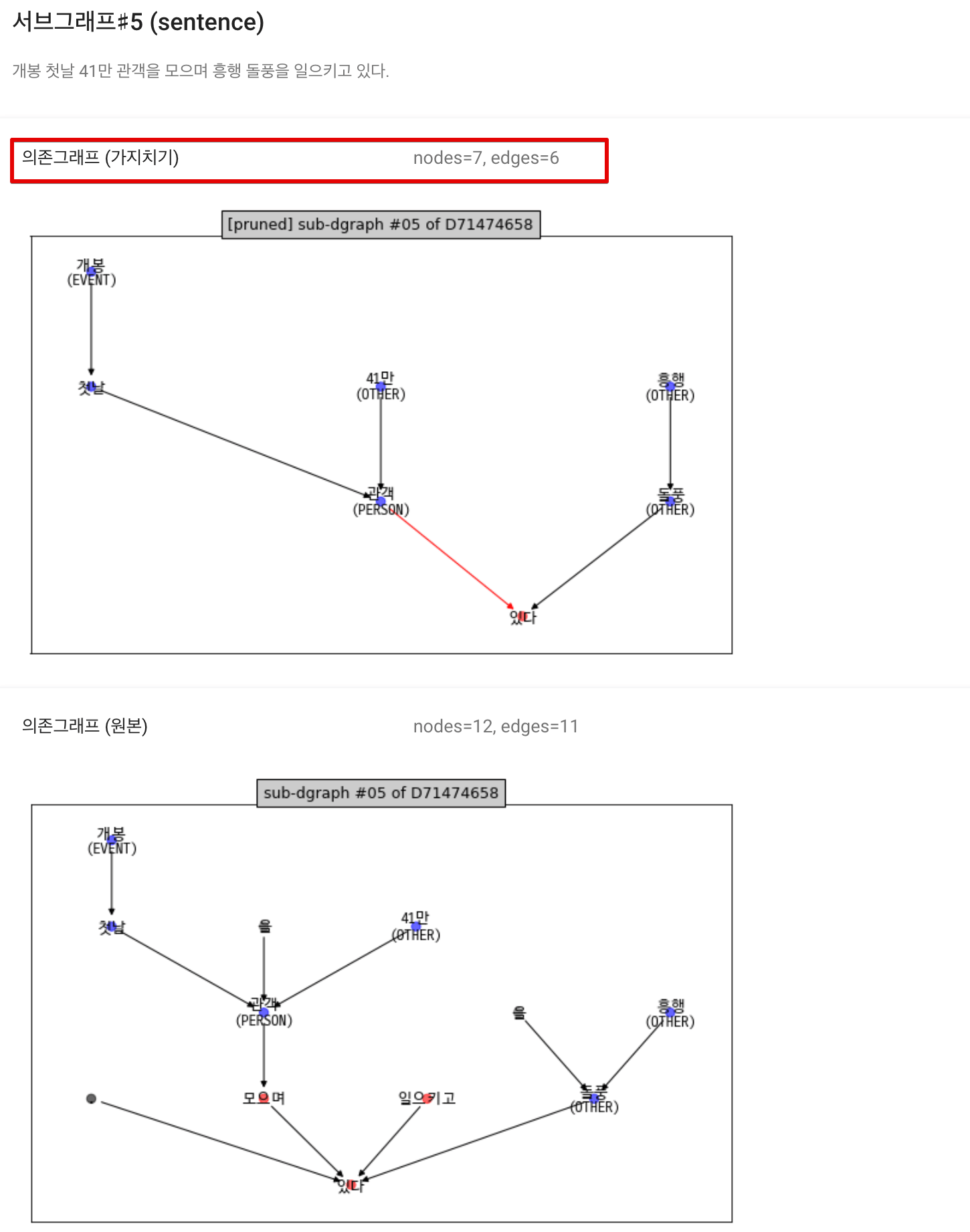
| <그림> 뉴스 샘플 - 문장 의존그래프 5번 |
6번 문장 “개봉 첫날 41만 관객을 모으며 흥행 돌풍을 일으키고 있다.”에 대한 의존그래프와 가지치기 결과에 대한 그래프 결과이다. 원본 문장의 경우 nodes=12, edges=11의 그래프 크기를 가졌는데, 가지치기의 이후 nodes=7, edges=6의 크기로 단순화 되었다.
텍스트 분석에서 Noise 제거는 분석 결과와 성능에 큰 영향을 미친다. 그래서 전처리에 많은 노력과 수고를 들인다. 텍스트에서 명사를 제외한 동사와 부사, 형용사 등은 문장의 의미를 구체화 하지만 형태적으로나 의미적으로도 변형이 많아 단순한 의미조차 결과를 도출하기 어렵게 만든다. 따라서, 원활한 자연어 처리를 위해 명사만 이용하는 방식이 많다.
의존그래프 데이터에서는 데이터 품질을 높이기 위해 가지치기(pruning)를 하는데, 자연어 분석을 위한 목적으로 leaf node와 bridge node를 제거하는 두단계로 구성하였다.
- 명사가 아닌 leaf node 제거
- 명사가 아닌 bridge node 제거
2번 작업의 경우, bridge node가 제거되면 그래프가 쪼개지는 문제가 발생한다. 그래서 cut-edge라고도 한다. 아래 그림은 bridge node를 제거하고, 새로운 substitute-edge를 연결한 결과이다.
 |
|---|
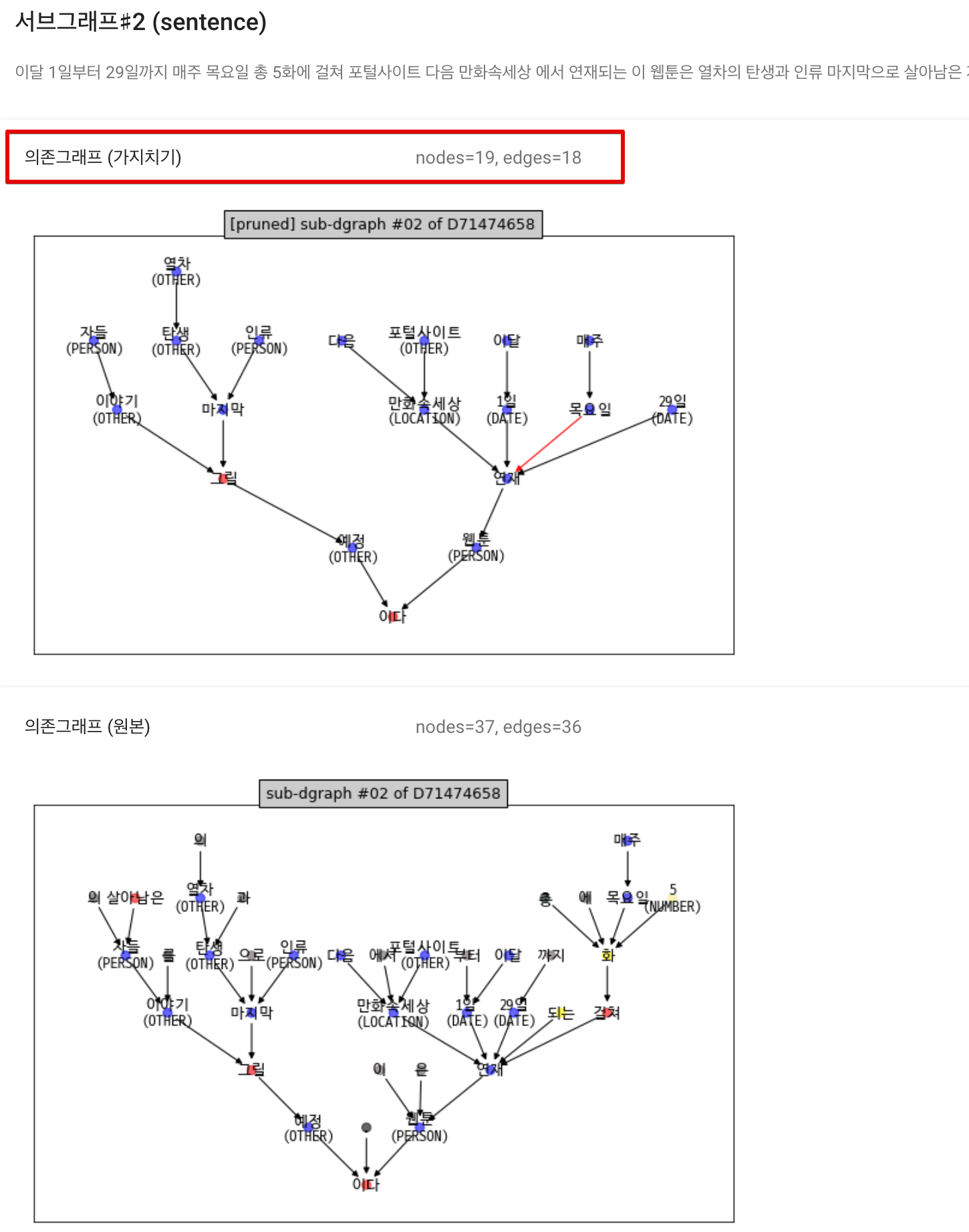
| <그림> 뉴스 샘플 - 문장 의존그래프 2번 |
“영화를 보고 영감을 얻어”라는 구절이 가지치기 작업을 통해 “영화-영감-얻어” 라는 구절로 변경 되었다. (가지가 두개 이상 연결되는 node 는 의미적으로 관계를 형성시키기 때문에 명사가 아니라 해도 제거할 수 없다고 전제했다)
이처럼 단순화시킨 그래프 데이터를 이용해 그래프 딥러닝(GNN) 기법들을 적용하여 지식그래프 구축 작업을 진행할 예정이다.
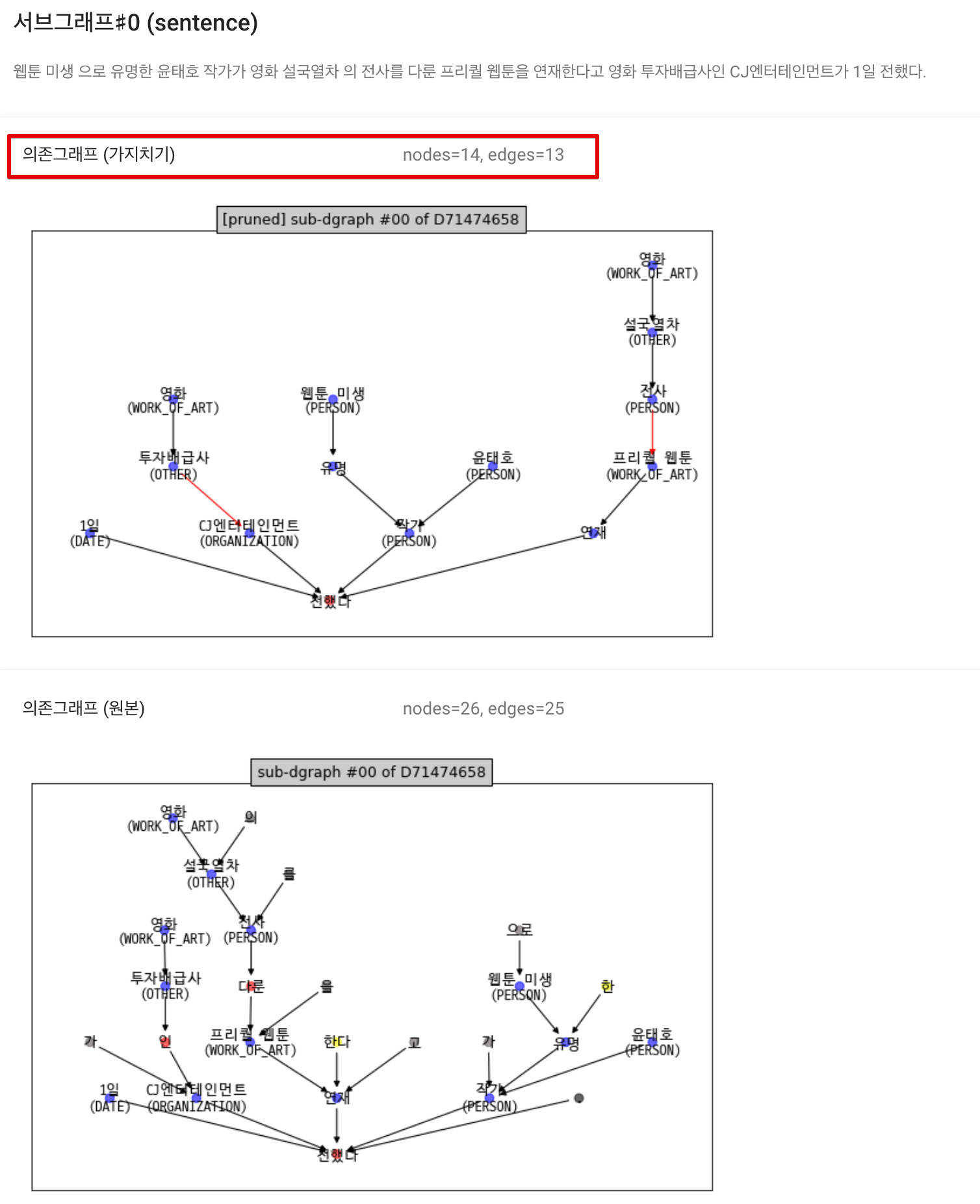
참고: 나머지 문장에 대한 캡쳐 화면들
 |
|---|
| <그림> 뉴스 샘플 - 문장 의존그래프 0번 |
|
|---|
| <그림> 뉴스 샘플 - 문장 의존그래프 2번 |
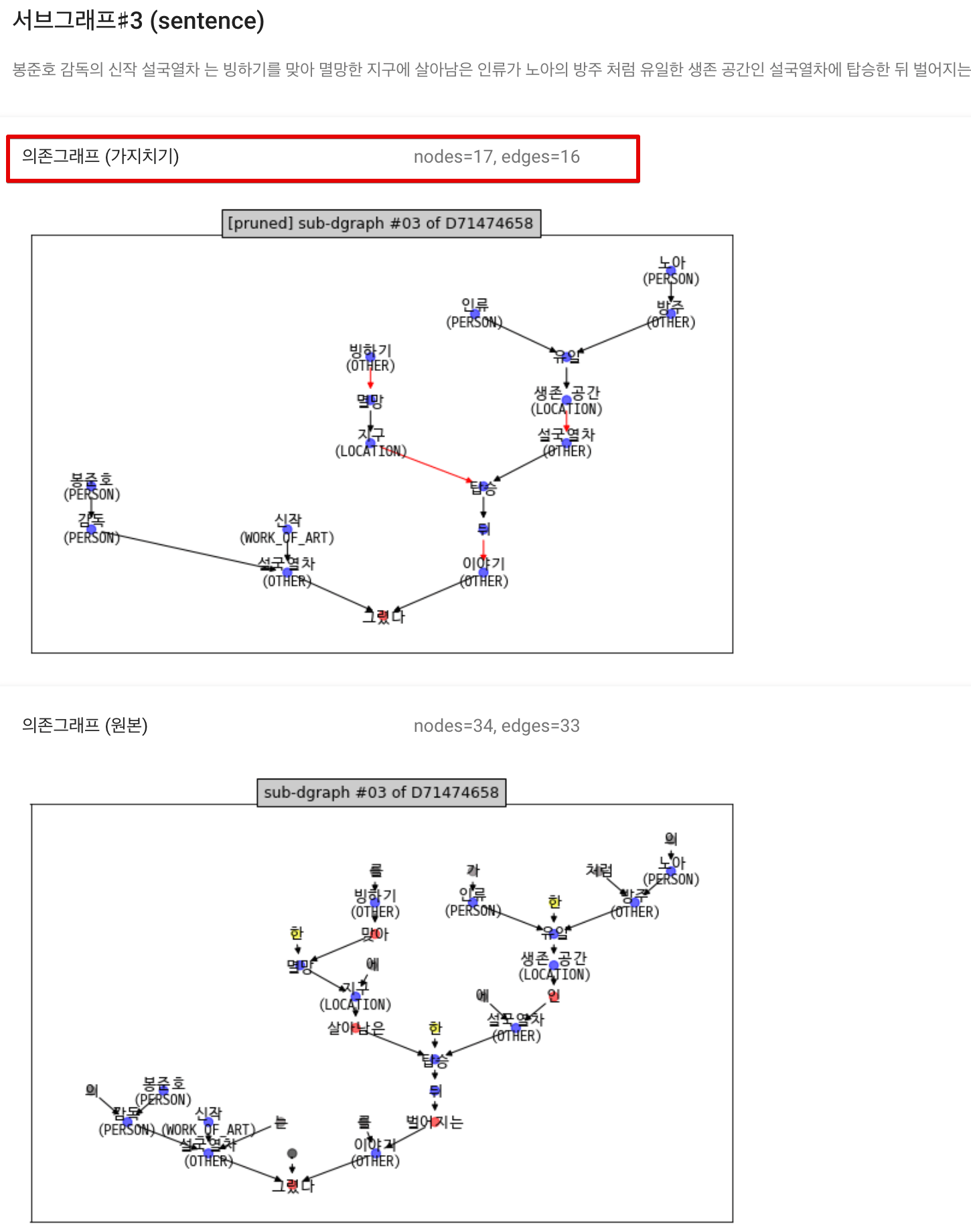 |
|---|
| <그림> 뉴스 샘플 - 문장 의존그래프 3번 |
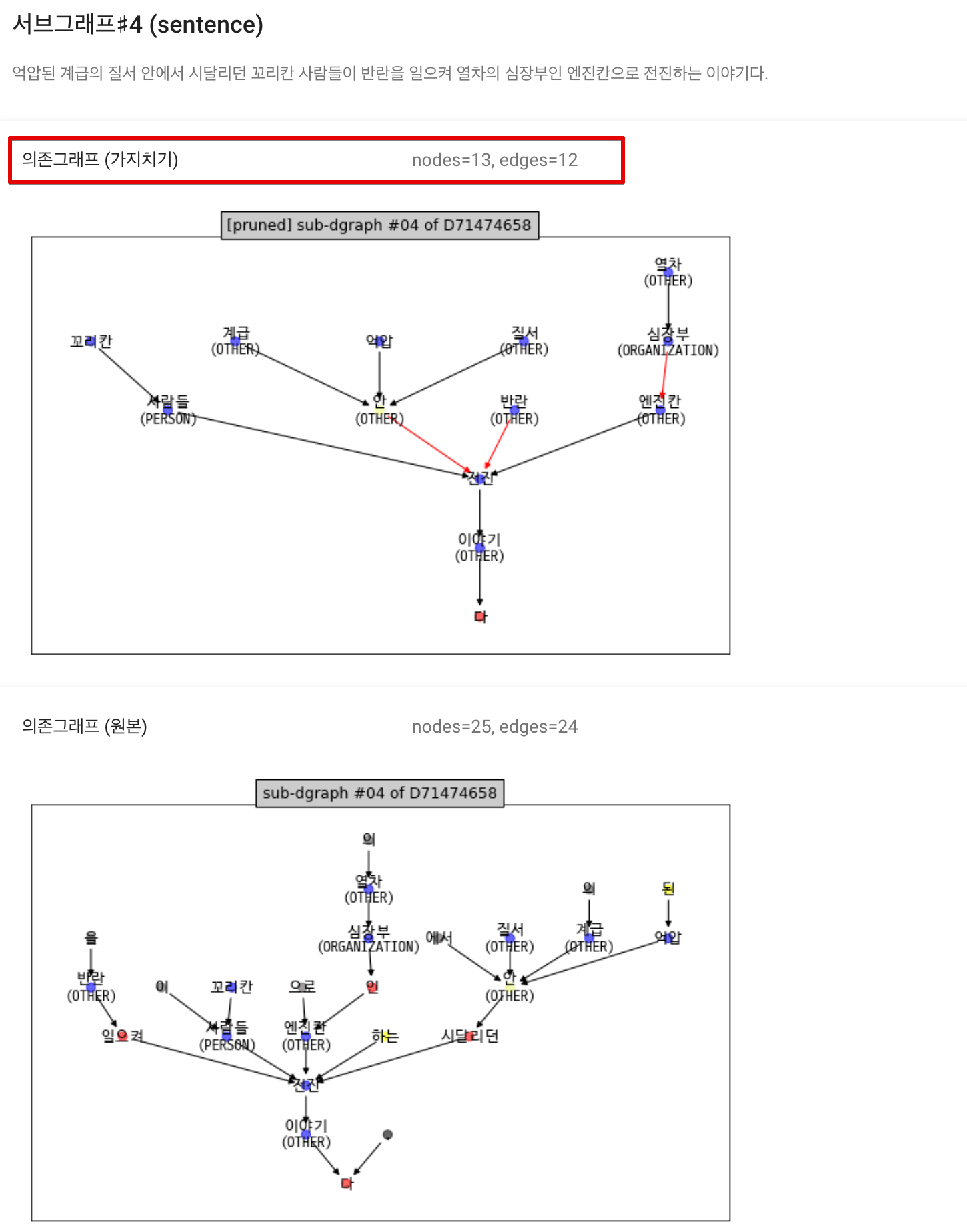 |
|---|
| <그림> 뉴스 샘플 - 문장 의존그래프 4번 |
본 연구에 대한 포스트는 태주네 블로그에 연재됩니다.
끝! 읽어주셔서 감사합니다.