텍스트로만 8GB 이상인 대용량 파일을 전처리 하기 위해서 빠르게 읽고 쓰는 방법에 대해 공부했습니다.
대용량 파일 읽고 처리하기
뉴스 JSON 파일 news.sources 용량 8.1G 를 읽고 JSON 문자열을 Document 개체로 변환하는 작업
- Type1: 일반적인 file open 이후, from_json 작업 수행 ==> 28분
- Type2: mmap 으로 메모리 맵핑 이후, from_json 작업 수행 ==> 13분
- 탁월한 성능 향상 체감

- tqdm 으로 진행률을 막대그래프로 출력
- 탁월한 성능 향상 체감
- Type3: mmap 으로 메모리 맵핑 이후, ThreadPoolExecutor 로 from_json 작업 수행 ==> 14분
- executor 작업을 위한 준비와 종료, 그리고 스위칭 시간 등으로 추가 시간 소요
- Process 와 Thread 차이
 |
|---|
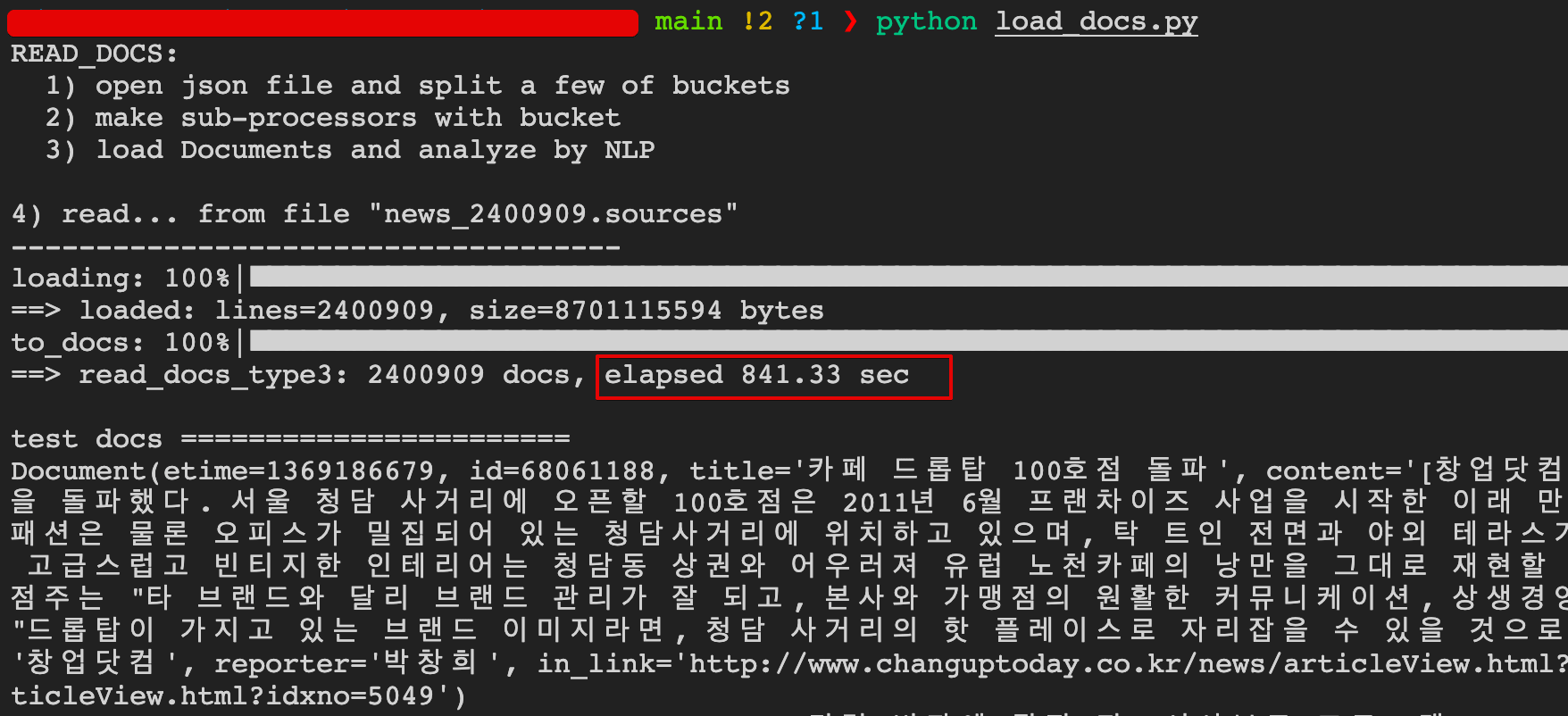
| <그림> Type3 실행결과 캡쳐 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
####################################################
## Type1: file.open and readline
##
def read_docs_type1(input_path: Path, fname: str):
rfile = input_path / fname
docs: List[Document] = list()
with rfile.open('r', encoding='utf-8') as fp:
for line in fp:
doc = Document.from_json(line)
docs.append( doc )
return docs
# ==> read_docs_type1: 2400909 docs, elapsed 1730.116 sec (28분) # file.readline
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
####################################################
## Type2: file.open and mmap.readline
##
## 파일을 메모리에 올린 후 읽기 (대용량 파일에 적합)
## ==> 확실히 빨라진다 (8.1G 파일 기준, 처리시간 포함해 28분이 13분으로 줄어듬)
import mmap
def read_docs_type2(input_path: Path, fname: str):
rfile = input_path / fname
docs: List[Document] = list()
with open(rfile, "r+b", encoding='utf-8') as f:
# length=0 mean 'whole of file'
map_file = mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ)
for line in iter(map_file.readline, b""): # read bytes
doc = Document.from_json(line)
docs.append( doc )
map_file.close() # must!!
return docs
# ==> read_docs_type2: 2400909 docs, elapsed 784.430 sec (13분) # mmap.readline
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
####################################################
## Type3: file.open and mmap.readline and ThreadPoolExecutor
##
## 파일을 메모리에 올린 후 스레드풀로 작업하기
import concurrent.futures as cf
from tqdm import tqdm
import os
def read_json_file(input_path: Path, fname: str):
rfile = input_path / fname
fsize = rfile.stat().st_size
tot_read = 0
lines: List[str] = list()
with tqdm(total=fsize, desc='loading', mininterval=0.5) as pbar:
with open(rfile, "r+b") as f: # binary mode (not need encoding)
# length=0 mean 'whole of file'
map_file = mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ)
for line in iter(map_file.readline, b""): # read bytes
lines.append( line )
tot_read += len(line)
pbar.update(tot_read - pbar.n)
map_file.close() # must!!
# 35초 소요
print(f'==> loaded: lines={len(lines)}, size={fsize} bytes')
return lines
# worker function
# 단위 작업 자체가 간소해서, Executor 를 사용하나 안하나 똑같다
# ==> 사용한 경우 13분, 사용한 경우 14분 (준비 및 종료시간 추가)
def conv2doc(line:str):
doc = Document.from_json(line)
return doc
# executor function
def read_docs_type3(input_path: Path, fname: str):
# read lines
lines = read_json_file(input_path, fname)
# results
docs: List[Document] = list()
num_cores = min(32, os.cpu_count() + 4) # Python 3.8부터 기본값
with cf.ThreadPoolExecutor(max_workers=num_cores) as executor:
with tqdm(total=len(lines), desc='to_docs') as pbar:
futures = [executor.submit(conv2doc, line) for line in lines]
for future in cf.as_completed(futures):
docs.append( future.result() ) # doc
pbar.update(1)
# ==> read_docs_type3: 2400909 docs, elapsed 841.33 sec (14분)
return docs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import sys
import time
from pathlib import Path
if __name__ == '__main__' :
print(f'1) read... from file "{fname}"')
print('------------------------------------')
start_time = time.perf_counter()
docs = read_docs_type3(input_path, fname)
elapsed_time = time.perf_counter() - start_time
print(f'==> read_docs_type3: {len(docs)} docs, elapsed {round(elapsed_time,2):3.2f} sec')
print('')
# ==> read_docs_type1: 2400909 docs, elapsed 1730.116 sec (28분) # file.readline
# ==> read_docs_type2: 2400909 docs, elapsed 784.430 sec (13분) # mmap.readline
# ==> read_docs_type3: 2400909 docs, elapsed 841.33 sec (14분) # mmap.readline + ThreadPoolExecutor
끝! 읽어주셔서 감사합니다.